Background and Purpose
What is Face Live Detection?
- Face Live Detection is a service for judging whether a face in an image is a real person (living body)
- In some strictly regulated businesses, we need to verify whether the operator is a real person, so in addition to Face Recognition, we often need to perform a “whether it is a real person (live)” judgment, that is, Face Live Detection
- The criminal industry often uses fake faces (non-live) to try to pass the verification, some examples of non-live attacks
Screen Photo Cutting paper Mask 



Why do we need a self-developed Face Live Detection Service?
- Many of the company’s services require real-name authentication and personal operation, the daily business volume is enormous, and the demand for business expansion continues to grow.
- In the past, we used Face Live Detection interfaces provided by third-party companies like Tencent or SenseTime, which cost a lot every year
- Advantages of self-developed Face Live Detection Service
- Complete or partial replacement of third-party interfaces, resulting in cost savings
- Join the SaaS platform built by the company and provide services to other companies, which can bring income as well
Achievements
Has the product been launched successfully?
- Yes, it’s a successful product and goes as expected
- It has been embedded in all our company’s Apps and works as the primary channel now, which satisfies over 80% of the total requests
- It has also joined the Yeahka AI cloud platform and provides service to other companies
- Demo Video
What awards/achievements has it received?
- Company’s Best Project of the Month
- Patent: “Facial Anti-fraud Method, Terminal Device, and Computer-readable Storage Medium”
- First author
- Patent number: CN202110563614.0
Overview of The Process
What is the process of Face Live Detection?
- As shown in the figure, there are three steps: Face quality detection, Action live detection, and Silent live detection, which is conducted on the mobile side and server side respectively.
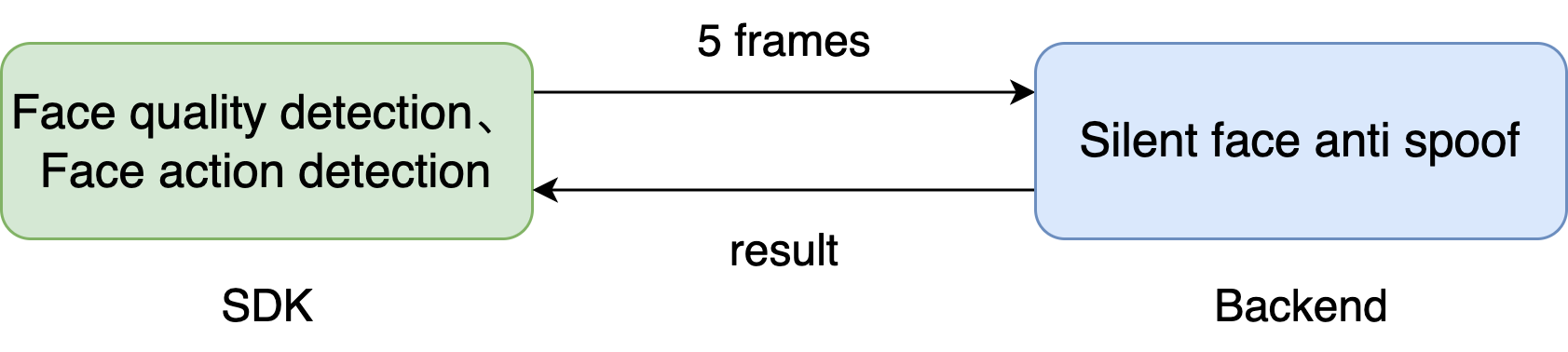
- Flow Chart
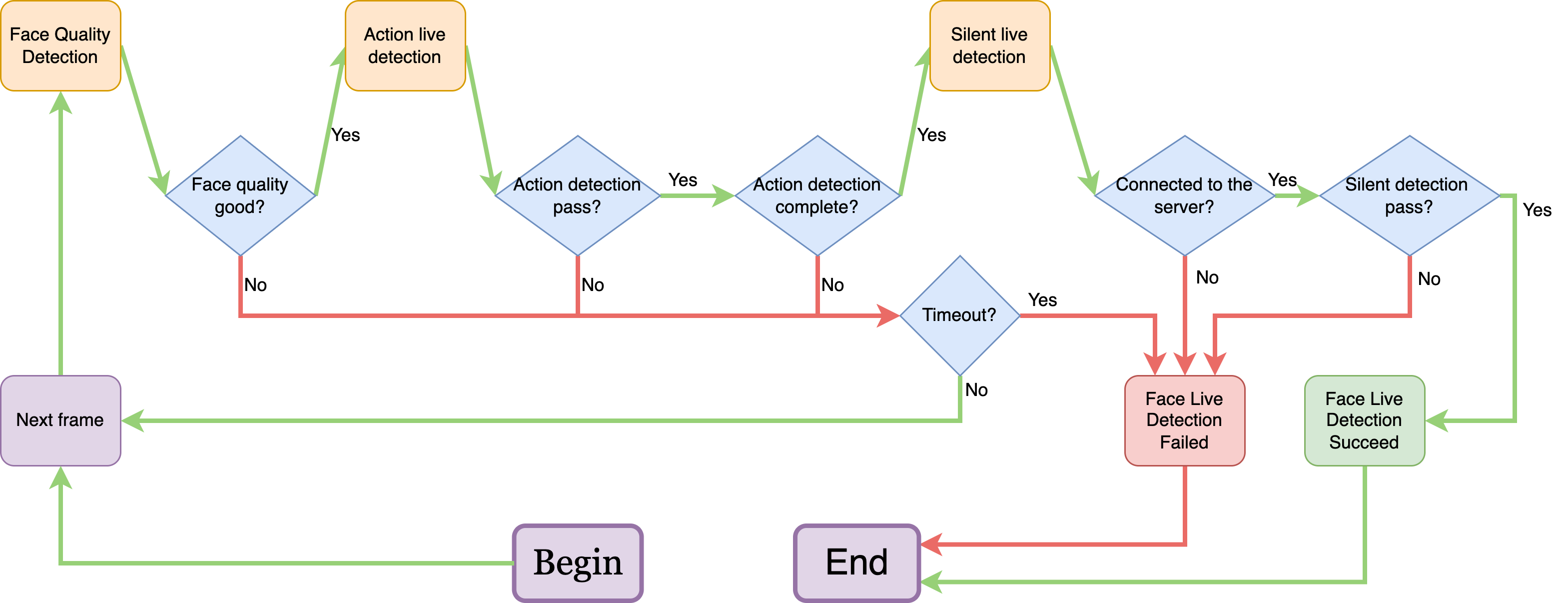
What do Face quality, Action live, and Silent live detection mean?
- Face quality detection: Make sure the image is not shaking, faces are present, and the lighting is normal
- Action live detection: Specify random actions such as mouth opening, eye blinking, and head turning. If the user completes the actions correctly, detection is passed; otherwise, they will be blocked
- Silent live detection: Detect the material in the picture and whether there are moiré, distortion, screen borders, or other attack features
Face quality(❌) Face quality(❌) mouth opening(❌) Silent live detect(❌) Silent live detect(✅) 




Why is silent live detection conducted on the server side?
- Small models do not perform well in identifying attack features such as moire or deformation, and large models are required.
- Large models require high computing power and cannot be deployed on the mobile side
Why are there three steps, not one?
- First step: Face quality detection
- Ensure that the image illumination is normal and there is no jitter, eliminate abnormal situations and improve subsequent algorithm accuracy
- Second step: Action live detection
- By specifying random face actions, most attacks (such as masks with unchanged face action) can be filtered out on the mobile side, which can reduce the pressure on the server side
Challenges - Server Side
How was the Action LiveDetect solution determined?
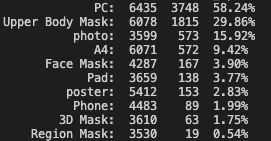
- Technology research
- Evaluation metrics: FRR (False Reject Rate), FAR (False Accept Rate) and HTER
- Traditional solutions
- Color texture (best result in the traditional solutions): 2~3%HTER,
- Other traditional solutions are usually 14~20%HTER
- Deep learning solutions
- CVPR2019、2020: 1~2%HTER
- The best one before 2021 is proposed by Tencent: 1.24%HTER
- The impact of datasets distribution differences
- Through the paper, it is found that the existing cutting-edge models can achieve good results for the same distribution of training tests, and the difference in HTER is not significant.
- But if the trainset and testset distribution difference is large, it has a significant impact
- The test results of the worse model, trained on the good data set, far exceed the test results of the better model trained on the bad data set
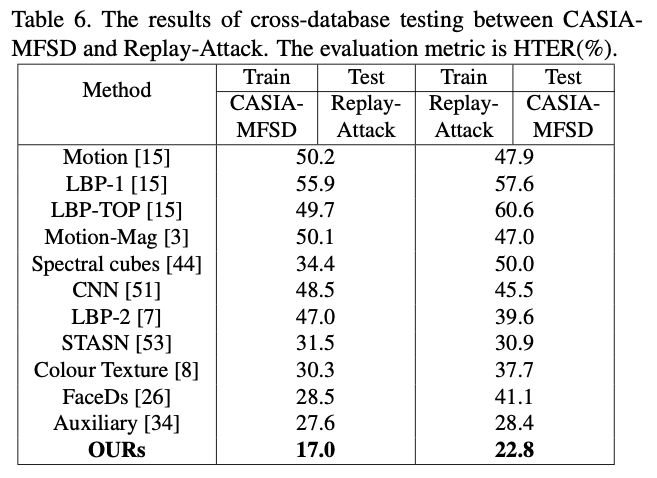
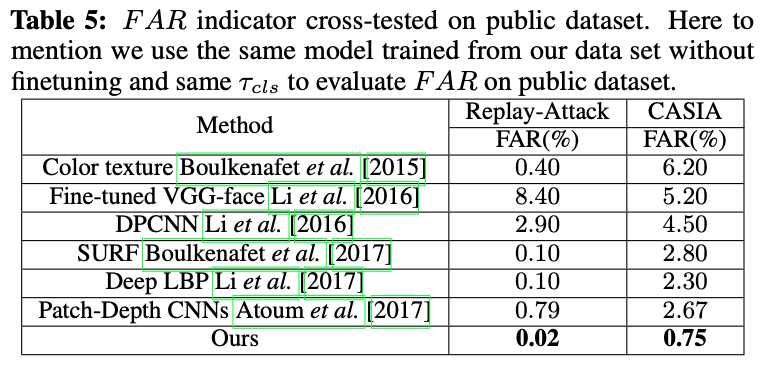
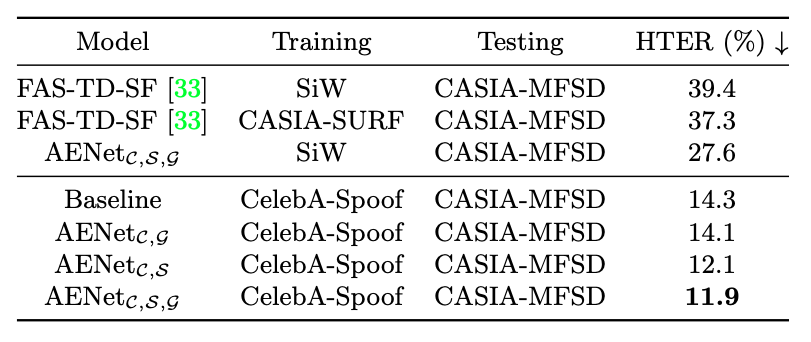
- Experiments
- Try multiple projects, including FaceBagNet@CVPR19-2nd、CDCN@CVPR20-1st, and [SGTD@CVPR20-2nd; some drawbacks are summarized below
- the result is not good enough
- Continuous frames are required; this is infeasible for real-time processing due to bandwidth limitations
- Depth label is required, which is not easy to obtain. If generate the depth label with PRNet, the inference speed does not meet the real-time requirement
- Even without generating the depth label, the infer speed is still too slow to meet real-time requirements due to extensive calculation
- The distribution of the dataset used in the paper is too homogeneous, and the trained model does not perform well in our real dataset (HTER>20%)
- Works well for 2D fraud problems, but not for 3D masks
- MiniFASNet@MiniVision
- Good test result, best performance among all models, cross-dataset result ~10% HTER
- Good test result, best performance among all models, cross-dataset result ~10% HTER
- Try multiple projects, including FaceBagNet@CVPR19-2nd、CDCN@CVPR20-1st, and [SGTD@CVPR20-2nd; some drawbacks are summarized below
How to make the result better?
- Optimize from data
- Open-source dataset: including CASIA_FASD, Oulu_npu, LCC, and six other open-source datasets, more than 1.5 million images in total
- Self-made dataset: Yeahka_FAS(private), more than 1.9 million images
- Cross-distributed datasets
- Examples of real-face dataset distribution
Normal Too bright Too dark Backlight Fuzzy 



- Examples of fake-face dataset distribution
Moore grain Screen reflection Screen material Screen exposure distortion 


Photos Cut paper Mask 3D mask 
- Examples of real-face dataset distribution
- Model weakness analysis and creating dataset aimed at those weaknesses
- Voting mechanism
- Co-voting of models at multiple scales
Scale1.0(full face) model Scale1.5(close shot) model Scale2.7(long shot) model Focus on facial details Focus on the transition between the face and the background Focus on details like background, edges, etc 


- Voting on multiple frames
- Random actions like mouth opening and eye blinking can increase the difficulty
- The movement may cause the fake face to move or deflect, thus revealing a flaw
- Co-voting of models at multiple scales
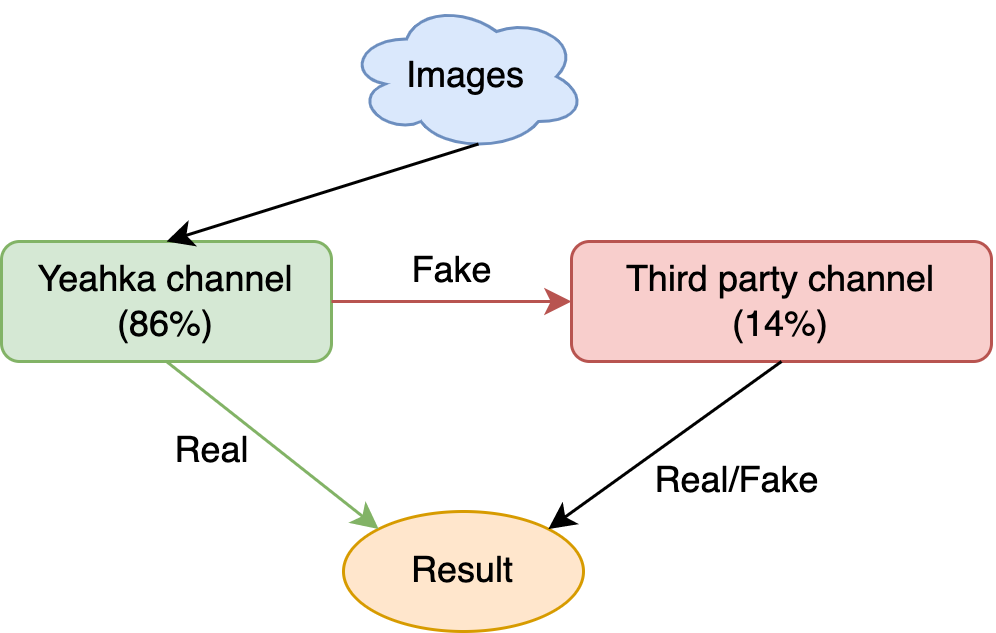
- Introduction of third-party channels
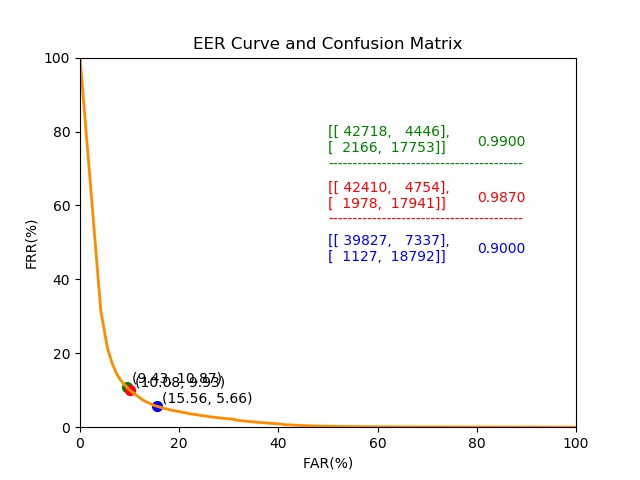
- Raise the threshold of the Yeahka channel to 0.99: FAR<0.01%, FRR~10%
- Results that Yeahka channel determines to be fake face are then sent to a third-party channel and returned with its result
- Final result
- Test 1000 images with fake faces, all of them were blocked, so the False Accept Rate is FAR=0%
- Test 16,000 images with real faces, and the False Reject Rate is FRR=0.7%, which is better than the third-party channel, as the figure shows below
- The requests for third-party channels decreased by 86.3%, which means 86.3 of every 100 requests can be satisfied by ourselves, and only the rest 13.7 requests need to request a third-party channel
FRR(%) Demands satisfied by Yeahka channel(%) 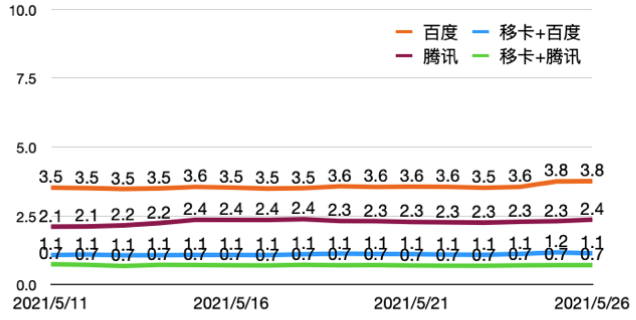
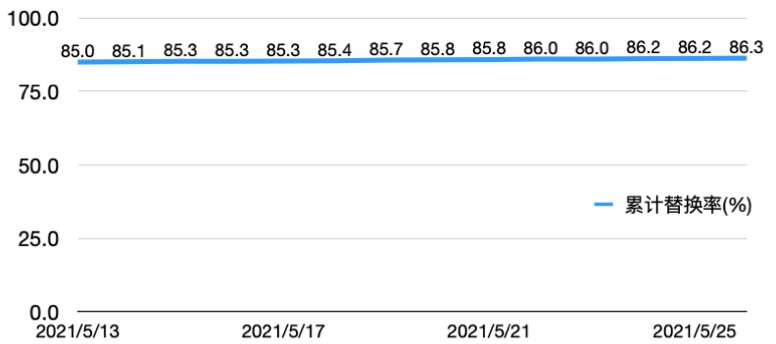
How to improve service stability?
- Module replacement
- Replacement between Scale1.0+Scale1.5 and Scale2.7 model
- If the face is too close for the Scale2.7 model to work, the Scale1.0+Scale1.5 model can also return results, and vice versa
- Replacement between the Yeahka channel and third-party channels
- If the Yeahka channel model fails, all requests will be forwarded to a third-party channel and return with its result
- Replacement between Scale1.0+Scale1.5 and Scale2.7 model
- Load balancing and disaster recovery system
- Multiple systems are deployed on different backend servers; the middle controller controls the forwarding of requests and evenly forwards them to different servers
- If a server returns an error/timeout, the middle controller will take it offline until the problem is fixed
- If multiple servers return an error/timeout, the middle controller will close the service and forwards all requests to a third-party channel
- Monitoring
- use supervisor service to monitor all processes of Yeahka channel and automatically restarts the process when it fails
- Regularly scan logs and send warning messages if found any module/system/service exception occurs
- Periodic request the interface; if the returned result is different from what is expected, a warning message will be sent
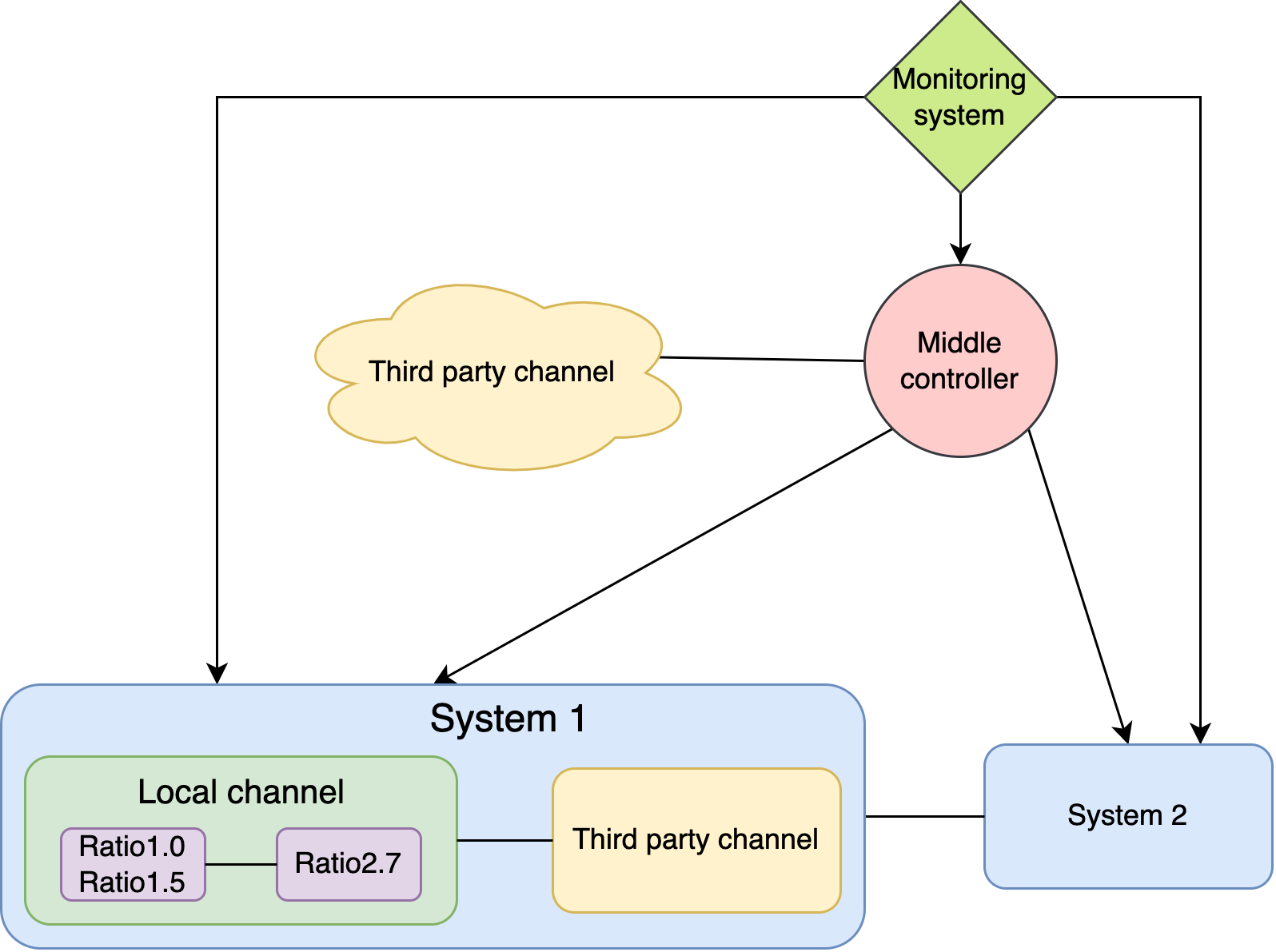
How to increase the concurrency of the service?
- Use gunicorn service to launch multiple processes, accepts requests concurrently, and evenly distributes CPU, GPU computing power and I/O
- Establish a TCP long connection between the middle controller and the backend server to transmit data, which can avoid repeated handshakes
- Cache the data and write once when needed, avoid repeated IO operations
- Locking mechanism to ensure the atomicity of operations when writing logs for multiple processes
- Avoid unnecessary calculations to optimize the speed
Challenges - Mobile Side
How was the Action Live Detection solution determined?
- Classify actions with classification model
- drawbacks
- Adding more actions or subtracting actions requires retraining of the model
- The face differences cause the model prone to misidentify
- drawbacks
- Mapping from 2D to 3D, using 2D key points to restore their 3D coordinates to determine the action
- Works well, correct orientation
- But it needs a large number of key points and is computationally intensive
- Reducing the number of key points will decrease the accuracy

- Guessing that the relative position of key points can infer the action
- Use the dlib package and find 68 face key points to verify the conjecture
- Found that nine face key points are enough for face action determination and give the code
Turn left Turn right bow Open mouth 
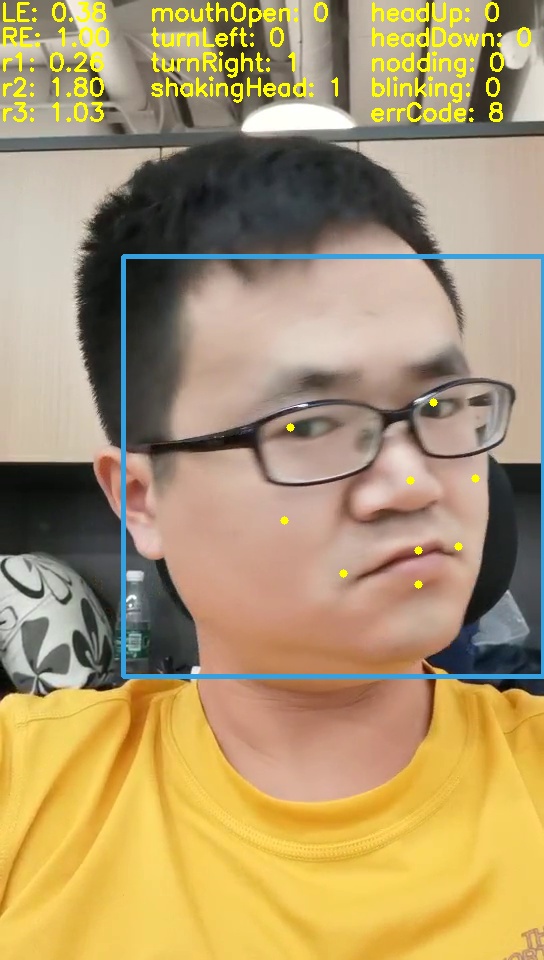
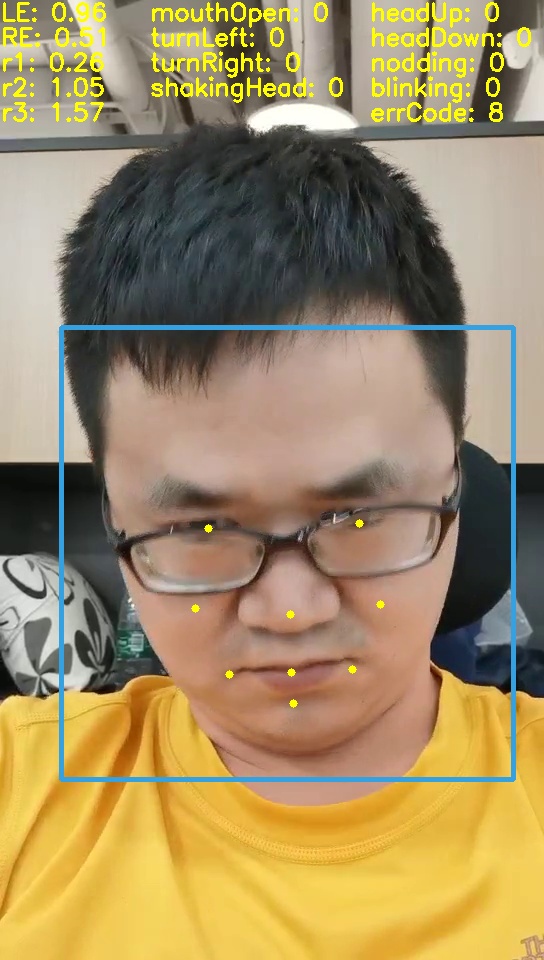
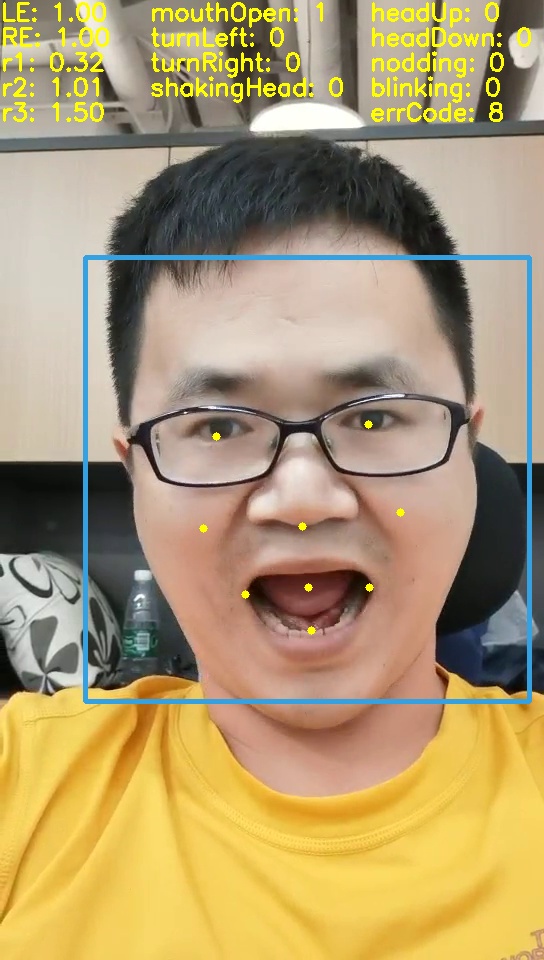
Any innovations in the algorithm?
- Multi-step merging
- Steps include face bbox determination, face key points determination, and whether the eyes closed
- Multiple steps are completed once using one model, which significantly reduces the inference time
- Reduce unnecessary calculations
- Discard smaller-face candidates while raising the thresholds of the three stages of MTCNN
- This step can discard those candidate frames with low probability and reduce the computational effort
- Exclusion of individual differences
- Multi-frame averaging to improve the accuracy of action recognition and reduce the false accepted rate
- Calculate the average static face, and determine the action by comparing it with the motionless face instead of determining the action directly from the threshold
- Targeted improvements
- Dark light, shake, and out-of-focus can affect the location of key points and thus affect the judgment of silent live detect model
- Propose the face quality detection step, which filters first to ensure that the picture is clear and bright
What is the structure of the mobile side?
- APP —> SDK —> .so dynamic library
- The APP can directly launch the SDK for face live detection, and the SDK will return whether the face is real or not
- The overall process is packed in the SDK, including UI interface, camera call and release, interaction with so dynamic library, interaction with the server, etc.
- The “.so” dynamic library packs all models and logic codes for face quality and face action detection algorithm, it interacts with outside through a fixed interface
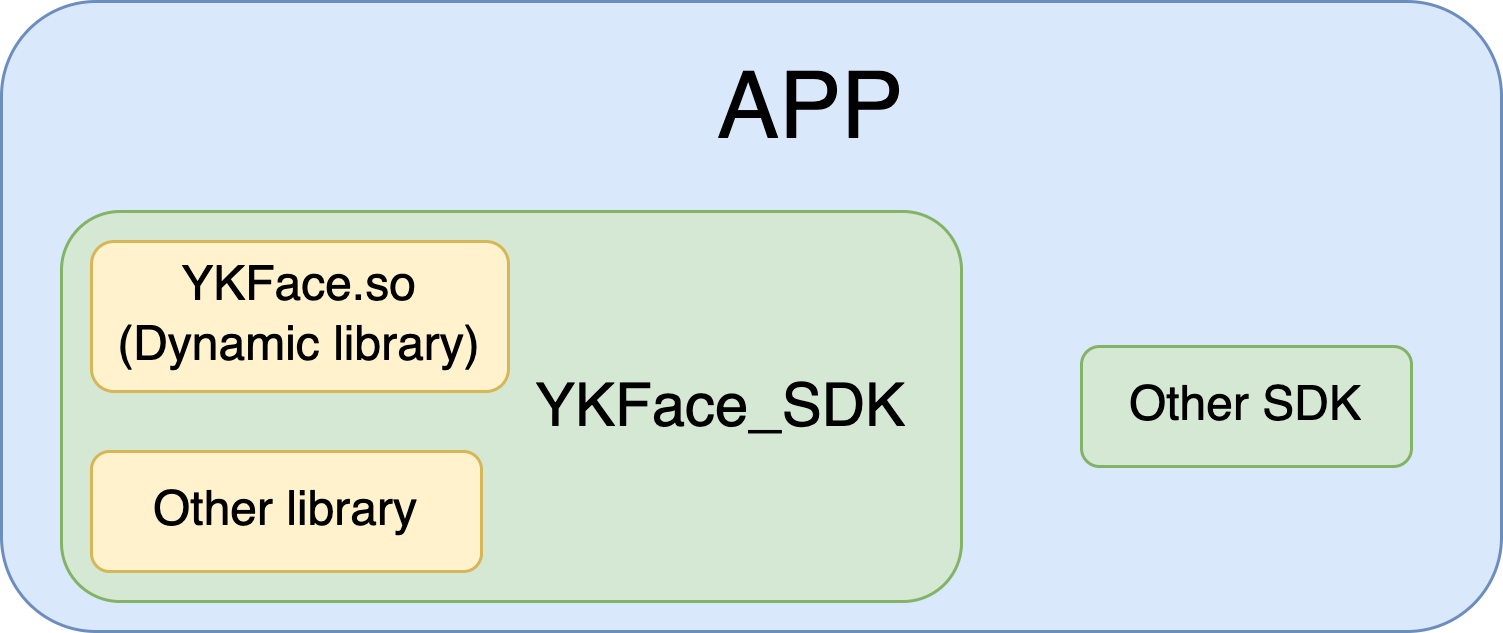
Why is the mobile side structure designed this way?
- The SDK adopts a modular design to package the overall process of face live detection, which is easy to embed in other Apps, also convenient for subsequent upgrades and maintenance
- The “.so” dynamic library is written in C++ so that Android can interact with it through JNI, and IOS can directly call it. The advantages are as follows
- Compatible with both Android and IOS systems; no need to repeat development
- Convenient for subsequent upgrades and maintenance in Apps, which only need to change the “.so” dynamic library
- Processing is fast
What engineering optimizations have been made?
- Memory management
- Use a fixed number threads pool with independent threads to analyze each frame collected; if all threads are in processing, subsequent frames will be discarded until there is a free thread
- Symmetric mapping for JNI in Android
- The Java layer object retains the pointer of the same name object in the C++ layer so that the java object can directly operate the C++ object through the pointer
- The mapping above replaces redundant copy actions during JNI interaction to speed up the processing
- The mapping can also be used to destroy the corresponding C++ object when the java object is recycled through Java Garbage Collection Mechanism, which is convenient for memory management
- File size optimization
- Rewrite the underlying logic of OpenCV used in image jitter detection so the “.so” library is not dependent on the “OpenCV.so” library anymore, and the SDK size is reduced
- Speed optimization
- Multi-threading for frame analysis in the java layer
- In the C++ layer, it also enables multi-threading to do forward inference using the ncnn library
- Interaction optimization
- Model iteration to improve accuracy
- Modified the user prompt logic, making the interaction more reasonable
Notes
ColorTexture
- Living and non-living faces are difficult to distinguish in RGB space, but there is a clear difference in texture in other color spaces
- Using face multi-level LBP feature in HSV space and the LPQ feature in YCbCr space, draw the histograms of each channel, send the concated result to SVM for classification
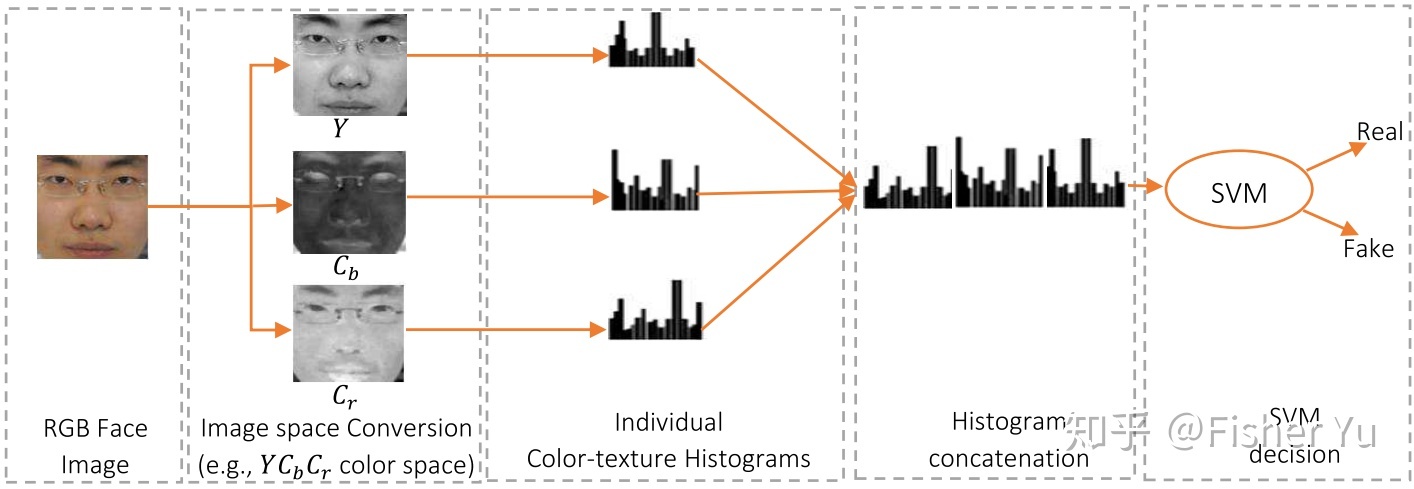
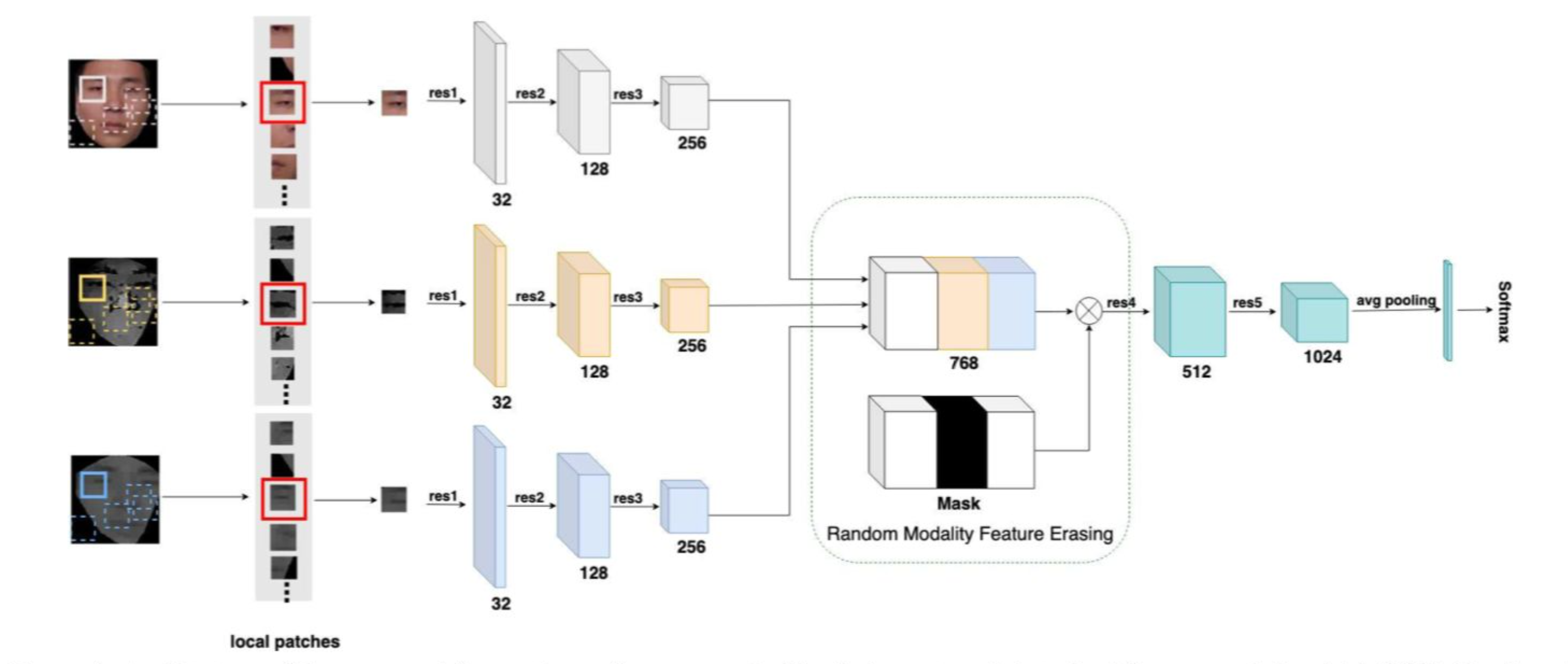
FaceBagNet
- Train a CNN network with randomly clipped face regions instead of full faces
- Randomly remove features from a modality during training to enhance generalization
- The structure of the backbone for extracting features mainly refers to ResNext
CDCN
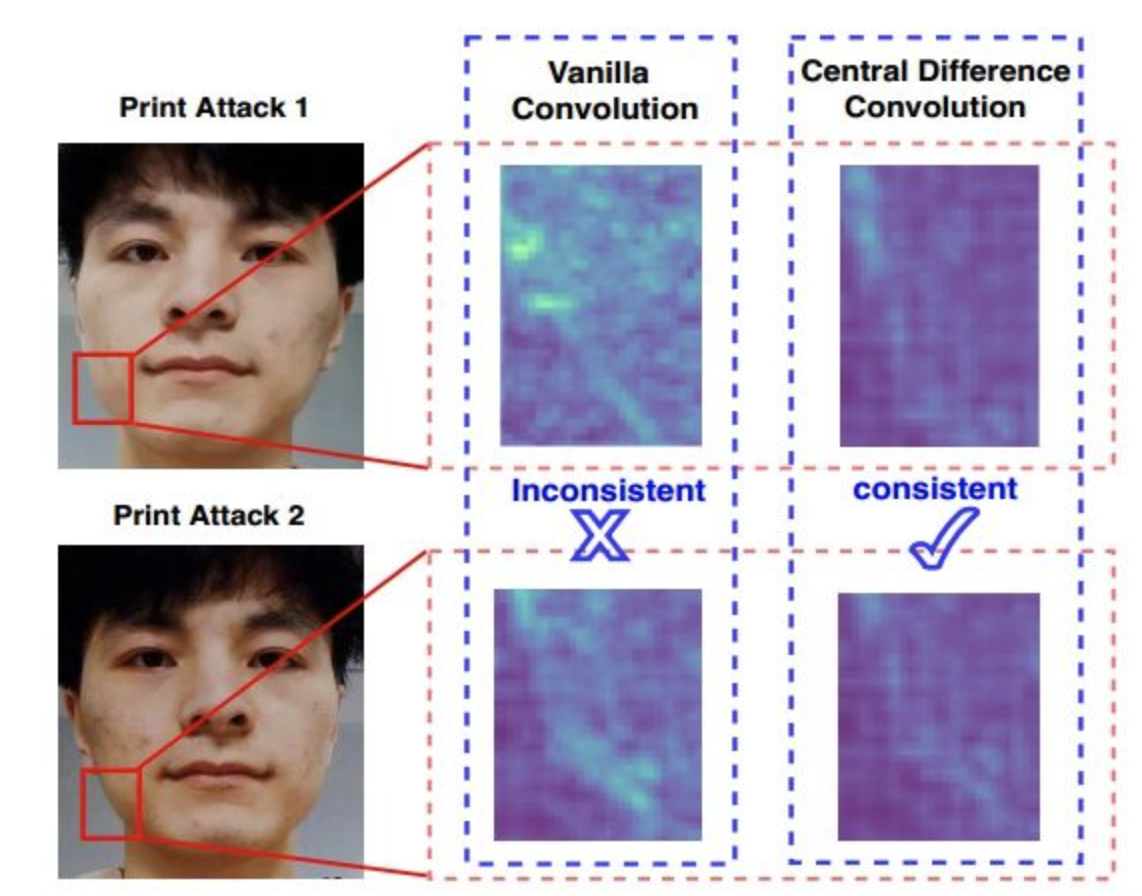
- Propose the central differential convolution (CDC). The ordinary convolution is very easy to be affected by the illumination or input distribution difference; after using the CDC, the CNN can better capture the essential characteristics of spoofing and is not easily affected by the external environment.
- Introducing NAS to solve the FAS problem
SGTD
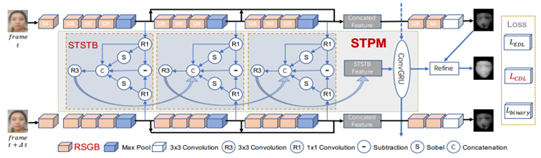
- To better characterize the spatial information, a Residual Spatial Gradient Block (RSGB) based on spatial gradient magnitude is proposed.
- To better characterize the temporal information, the Spatio-Temporal Propagation Module (STPM) is proposed.
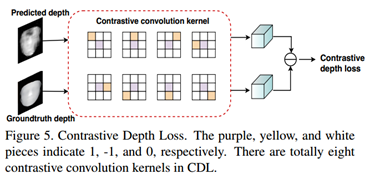
- To make CNN better learn the detailed spoofing patterns, a fine-grained supervision loss is proposed: Contrastive Depth Loss (CDL)
RSGB STPM CDL 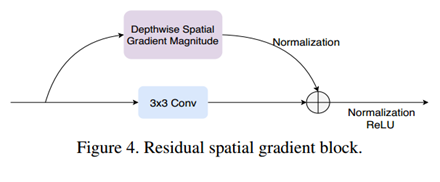
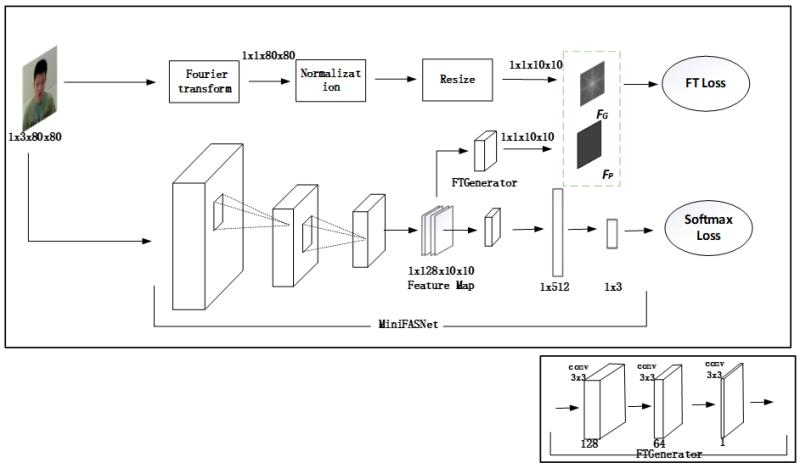
MiniFASNet
- Fourier spectrogram-assisted supervised detection method based on a model architecture consisting of a main classification branch and a Fourier spectrogram-assisted supervised branch
- Video introduction