Background and Purpose
What is pedestrian tracking and behavior recognition?
- Track multiple targets simultaneously in various views and identify their behavior in real-time
- Keywords: real-time, multi-view, multi-target, tracking, behavior recognition

Why do we need multiple views?
- The target is easily obscured in a single view; switching the view can reduce the obscuration and help to identify the behavior
- Multi-view makes continuous tracking possible, such as from one room to another

What can pedestrian tracking and behavior recognition do?
- We want to use it to provide better customer services, whether commercial tenants or individual businesses. Services include passenger flow analysis, hot spot detection, customer preferences analysis, abnormal behavior identification, etc.
- Explore the feasibility of intelligent retail or retail without people
- Video Understanding
- A surveillance video stream is just a pile of data; the information is unstructured, resulting in a large amount of redundant information exists, which increases the difficulty of video preservation, transmission, processing, and search
- Video comprehension is actually to structure the data, which helps with video compression and facilitates data search
Achievements
Has the product been launched, and how is it working?
- The system is deployed in the company library to serve colleagues; it also serves as a technical showcase
- Waiting for the deployment of the Automatic Goods Identification part and Self-service Payment part, which are in the developing process
- Restricted in generalization because of high upfront cost, and the accuracy of the feature extraction model needs to be improved
- The architecture of the whole system is already in the gradual improvement
What awards/achievements has it received?
- Company’s Best Project of the Month
- Patent: “Behavior Recognition Method, Device, Terminal Device, and Storage Medium”
- First author
- Patent number: CN202210321459.6
Overview of The Process
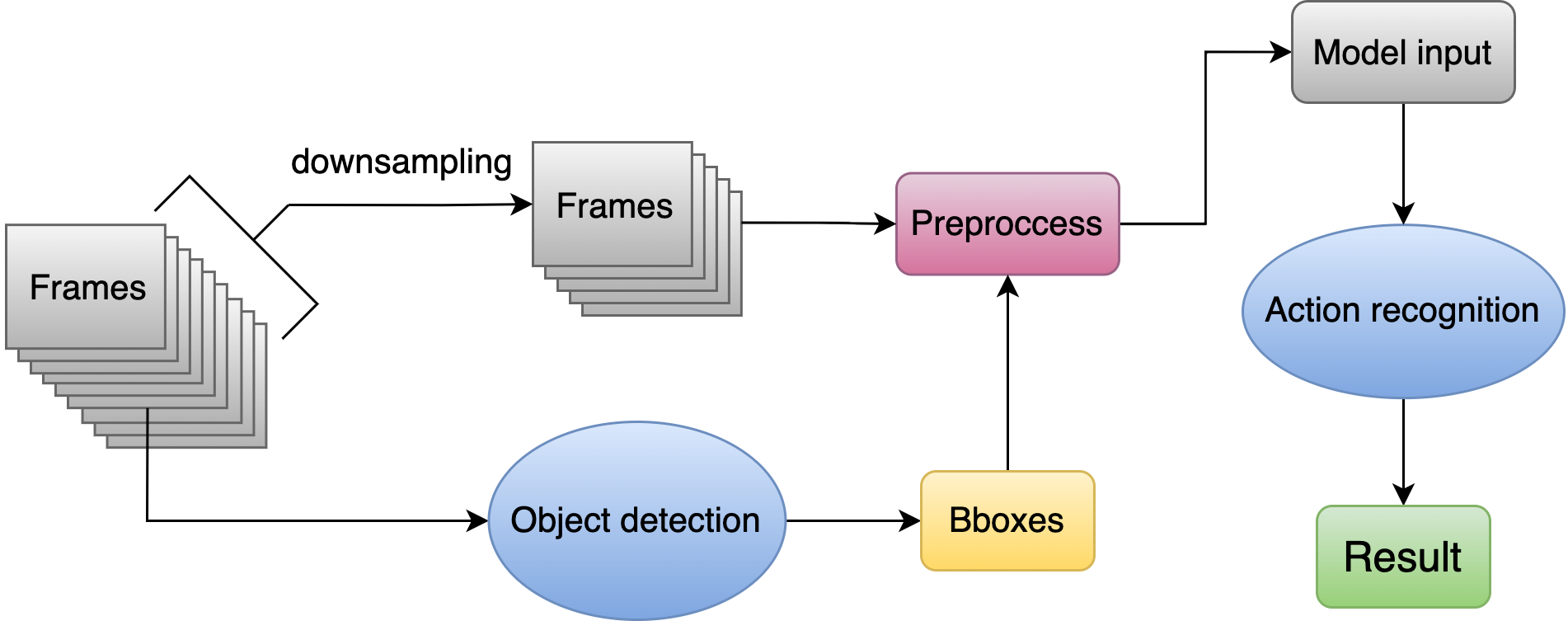
What is the structure of the whole process?
- As shown in the figure below, the process includes three parts: Video Input, Backend Server, and Front-end APP
- The Video Input part collects the video stream and sends it to Back-end Server using the RTSP protocol
- The Backend Server part carries out real-time tracking and identification and transmits the results to the Front-end APP part using RTSP protocol as well
- The Front-end App part displays real-time video results and interacts with the Backend Server through HTTP protocol at the same time, such as obtaining abnormal warnings
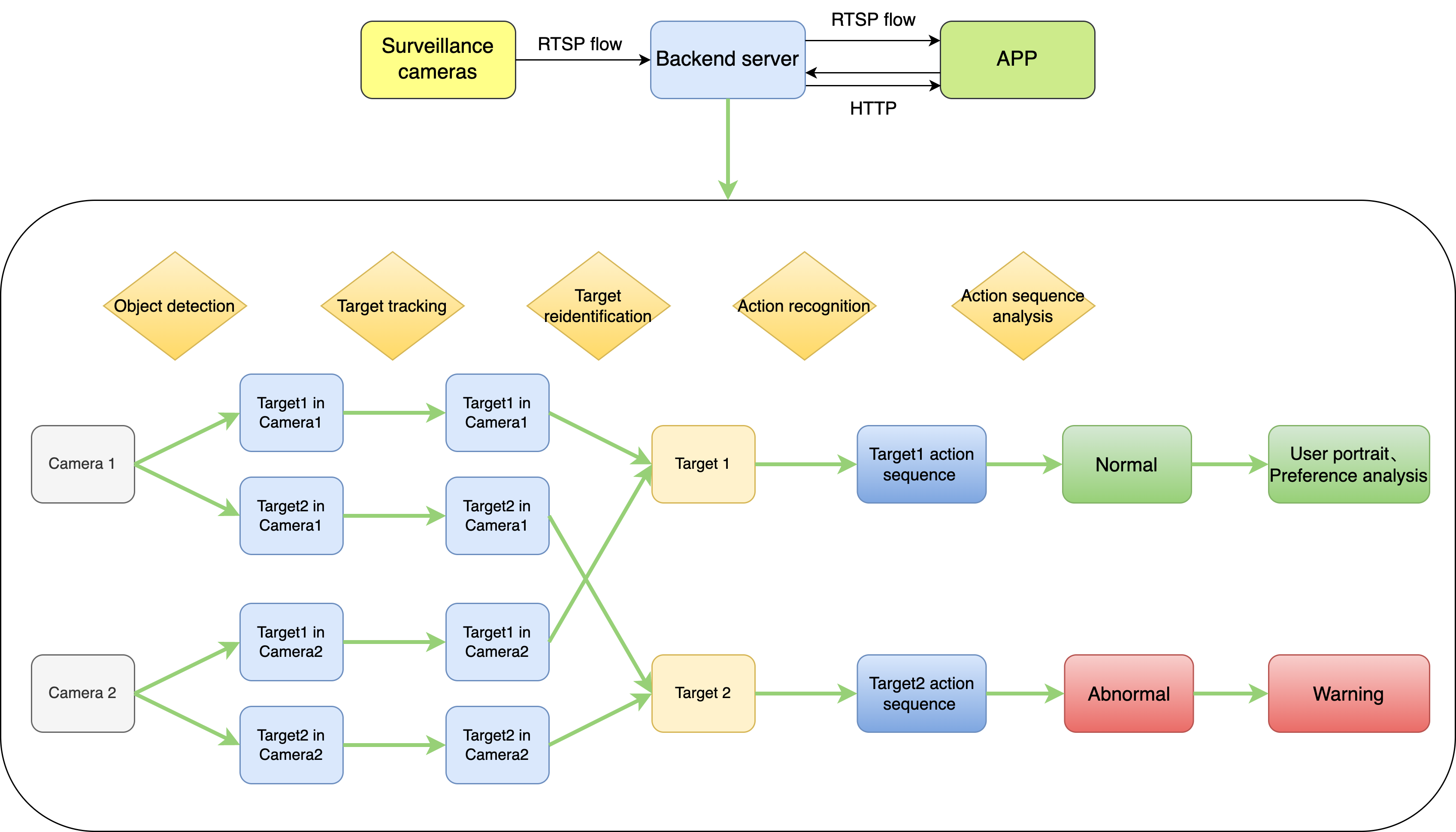
How does the Backend Server carry out tracking and identification?
- Do Object Detection in all views and get the bounding box for each pedestrian
- All viewpoints do pedestrian tracking and confirm the tracking target within each perspective
- Merge the same tracking target between different viewpoints by doing pedestrian re-identification(REID) between views to obtain global tracking targets
- Identify global targets’ basic behaviors, and make a basic behavior sequence for each target
- Analyze the basic behavior sequences and determine each target’s advanced behavior
Challenges - Algorithm Development
How to do pedestrian tracking?
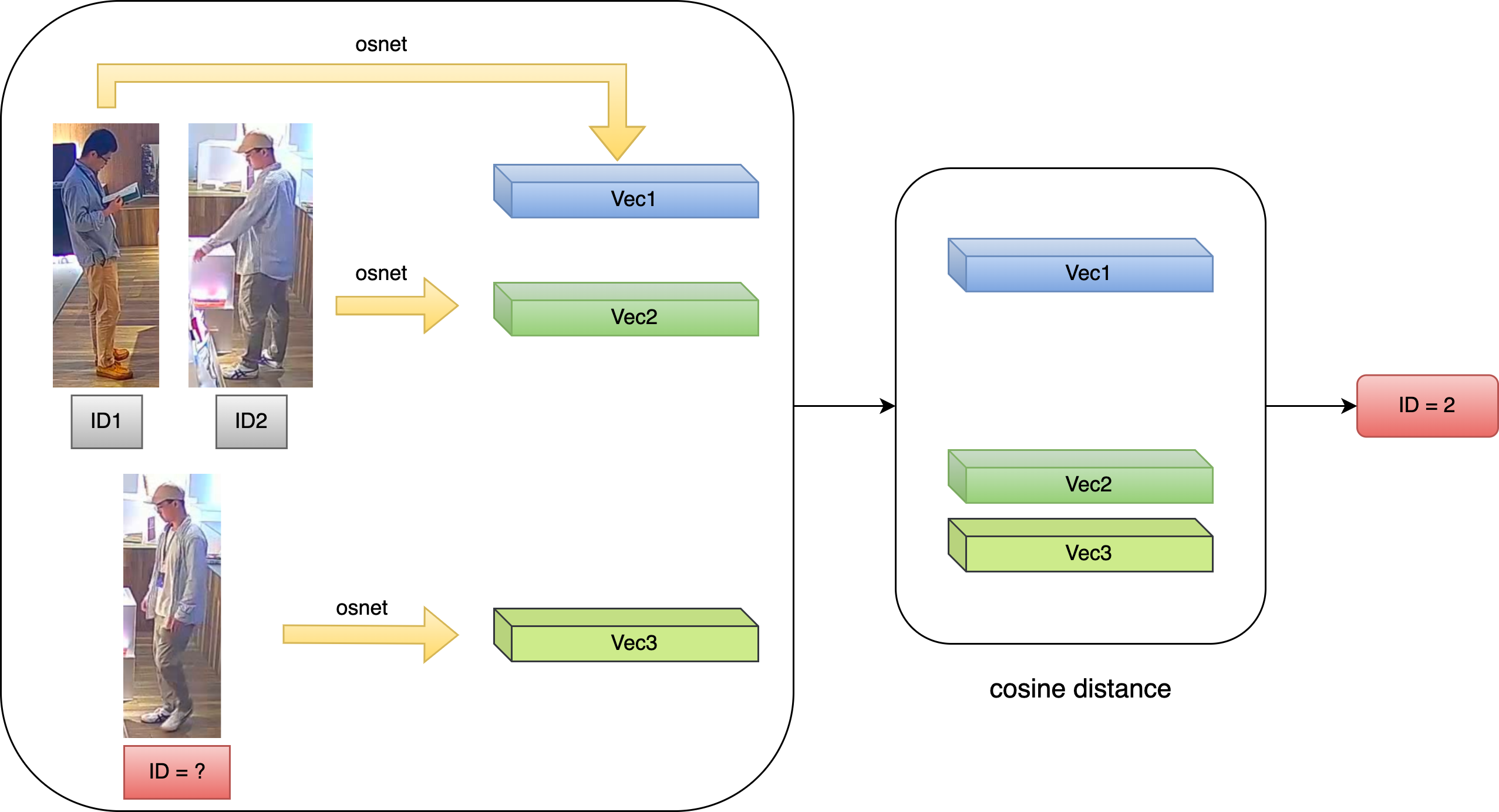
- Based on appearance feature similarity
- Use the target re-identification (REID) algorithm. Its principle is to train a feature extraction network to extract the appearance feature vector for each target and then calculate the cosine distance between the different feature vectors. Since the cosine distance between the feature vectors of the same target is smaller than that of other targets, matching can be performed
- Advantages
- Relatively high accuracy
- Disadvantages
- When the appearance is mutated (e.g., obscured), the appearance matching is prone to fail, thus causing target loss
- Feature extraction and cosine similarity matching are computationally intensive and time-consuming
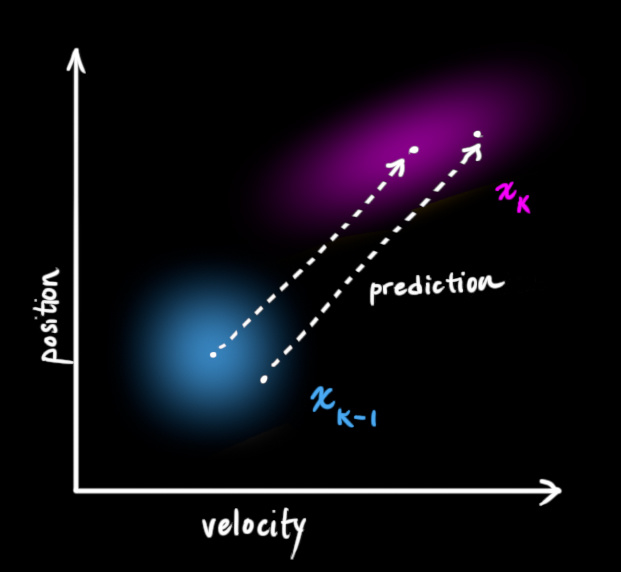
- Based on motion feature similarity
- Use the Kalman filtering algorithm. Its principle is that based on the target’s known position, size, and velocity in the previous frame, the mean and covariance of the target’s bounding box in the current frame can be predicted and then matched with the detected bounding boxes. The matched bboxes can be used to predict the position of the target in the next frame
- Advantages
- Matching can be done regardless of appearance features, even if partial occlusion occurs
- The amount of calculation is relatively more minor and thus has a faster computing speed
- Disadvantages
- It might be wrong when targets are interleaved

How to improve the accuracy and efficiency of tracking?
- Combination of the two: Matching based on motion + appearance features similarity
- In each step, the appearance features of pedestrians are extracted, and their positions are predicted at the same time; both the predicted bboxes and the appearance features are used for matching based on their similarity
- Advantages
- Motion-based and appearance-based matching methods can complement each other, reducing matching errors when targets are interleaved or targets’ appearances change abruptly
- Disadvantages
- Since each step needs to extract the appearance features of all detected bboxes, it is computationally intensive and slow.
- If the target disappears briefly and then reappears, it will be mistaken as a new target
- Any error that occurs in the appearance or motion match step can affect subsequent tracking results
Target lost New target 

- Faster match method: Motion match first, then appearance match
- The similarity of motion features is sufficient for matching in most cases, and the appearance feature extraction is not necessary at this point, and it will take up computational effort and reduce efficiency
- Human eye tracking is similar; in most cases, it is based on the location of the target, and only when necessary will it look closely at the appearance to distinguish the target
- So we do the motion feature matching first and then extract the appearance features for recognition when the motion matching fails (e.g., multiple detection bboxes near the tracking target), which can save computing effort and improve efficiency.
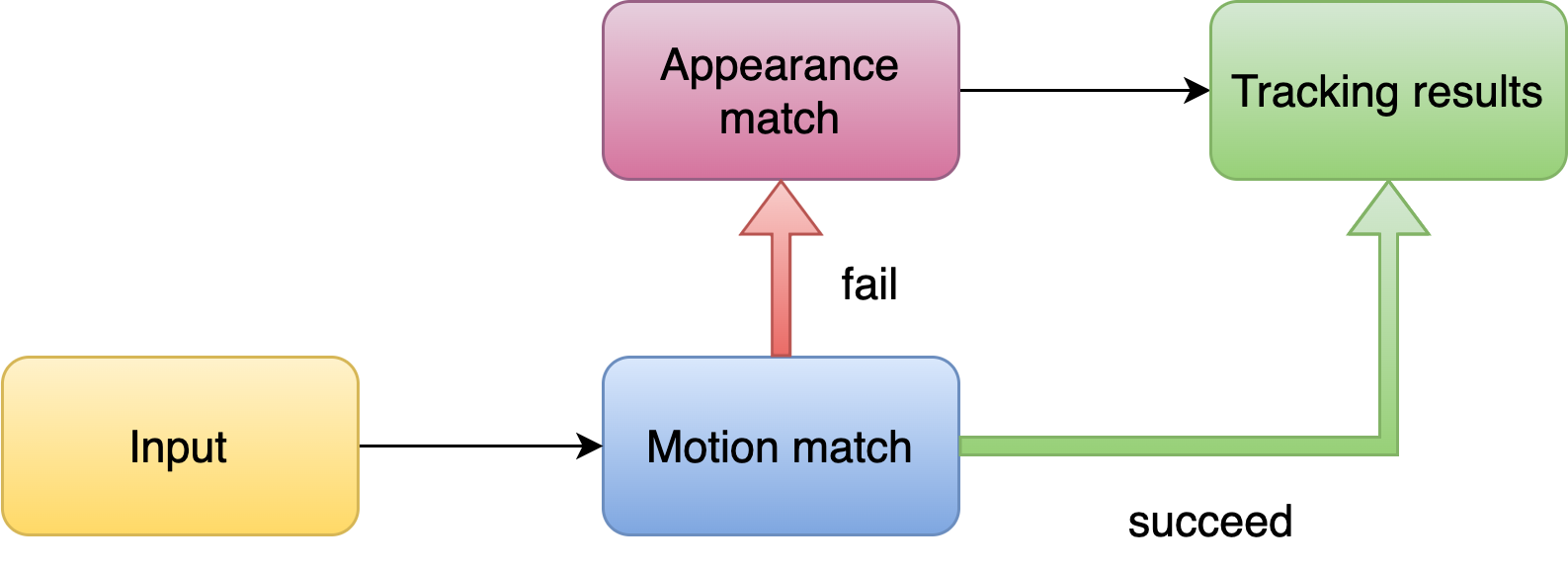
- More stable: Layer-by-Layer Matching Mechanism
- The appearance features of tracking targets are extracted and updated periodically, and the detection bbox is matched with each tracking target using the appearance feature each time; the closer the update time is, the more likely the target is matched first
- If the target disappears briefly, the detection bbox can be re-matched to the target from some time ago by the appearance features instead of being mistaken for a new target, which makes the tracking results more stable
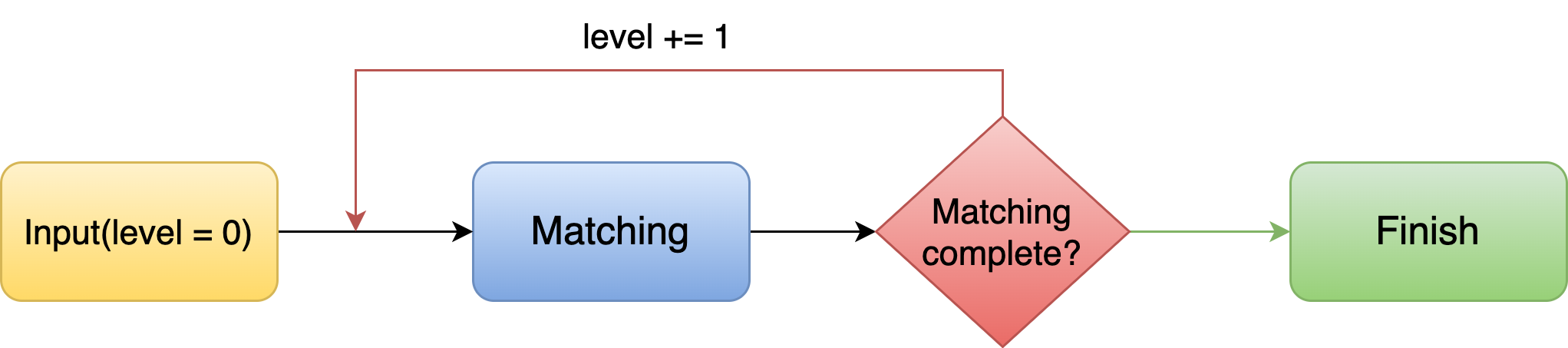
Target lost Rematch 
- More accurate: Appearance check
- Independent process to verify that the appearance of the same target remains consistent over time, preventing long-term tracking errors caused by short-term appearance matching errors
What behaviors need to be identified?
- Scenario: Bookstore
- Normal behavior: Getting and putting books, reading, sitting, standing, walking
- Abnormal behavior: Calling, raising hands (needing help)
- Purpose
- Getting book and reading behavior helps build user profiles for user preference analysis
- User stay time and trajectory are used for customer flow distribution and hot spot area analysis
- Calling and hand-raising behaviors are used to identify anomalies and assisted management
How to do behavior recognition?
- Human body key points + rules
- The rules are not easy to determine, resulting in inaccurate results
- High computing power requirements
- Classification by individual frames
- Advantages
- Some of the basic actions have appearance differences, such as getting books, reading, etc., which can be easily distinguished.
- Smaller and faster calculations
- Disadvantages
- Easy to be mistakenly identified
- Some actions need before and after frame information, such as reaching and retracting hands, which cannot be identified by one frame alone
- Unable to count the number of book pickups
Reading Pick up/put back the book misidentification 


- Advantages
- Classification by continuous frames
- Data pre-processing
- Downsampling, cropping, scaling, padding, etc.
- Purpose: Keep the image undistorted, retain valid information, discard irrelevant information
Pick up a book Put back a book 

- Algorithms
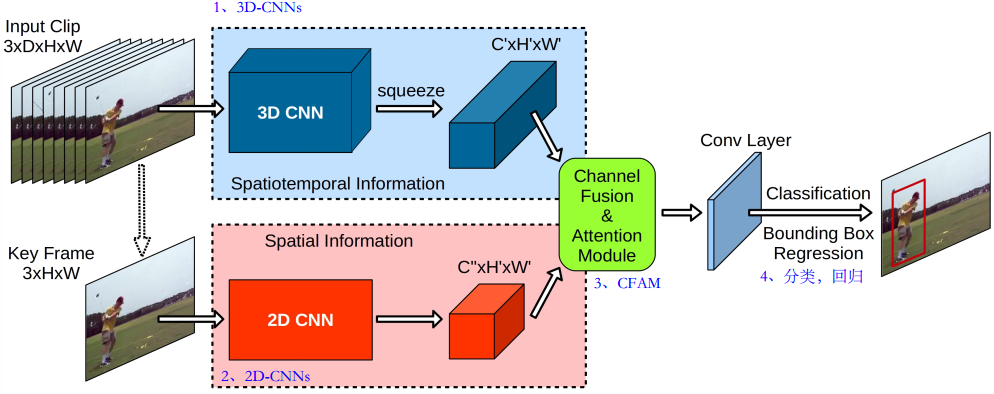
- YOWO
- clip as a whole is fed into 3DCNN, which is used to model the time information
- The keyframes in the clip are fed into 2DCNN, which is used to model the spatial information
- Then spatial and temporal features are sent to CAFM for fusion
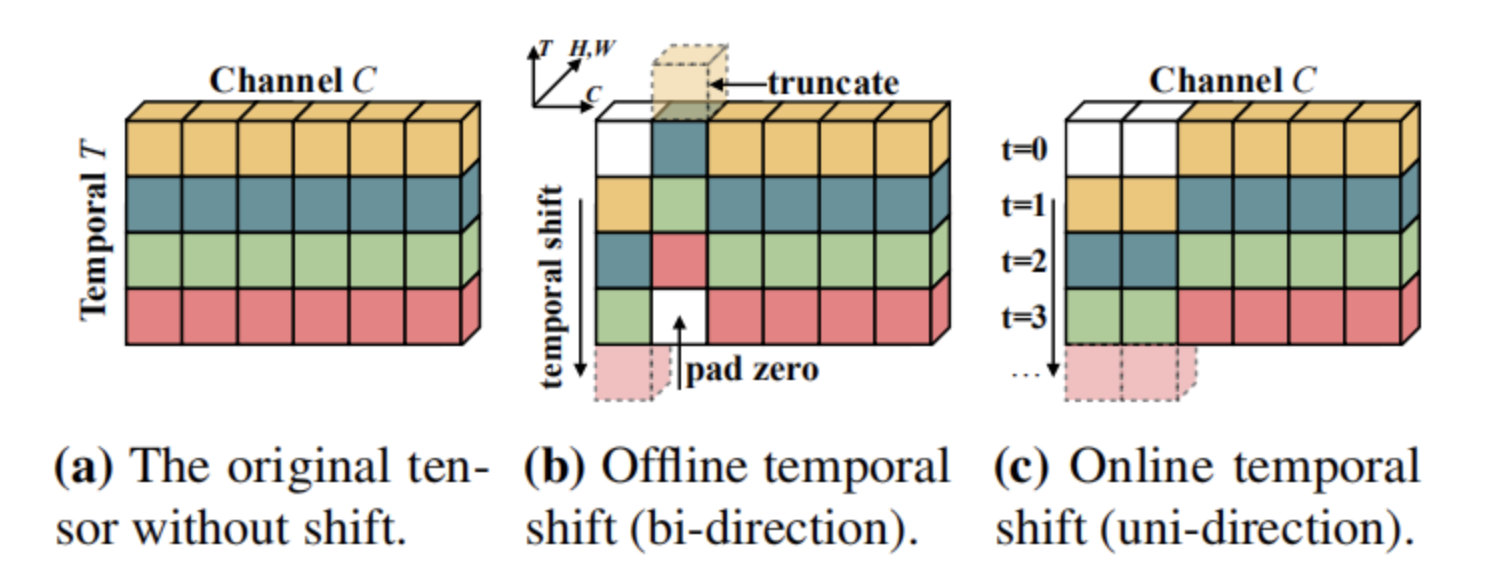
- TSM
- Move part of the channels in the time dimension, thus facilitating the information exchange between adjacent frames (modeling of time)
- The effect of 3DCNN is achieved using 2DCNN
- Real-time, low latency, more accurate and efficient
- YOWO
- Data pre-processing
Challenges - Algorithm Deployment
How to achieve real-time processing?
- Necessary processing steps: Video stream input, Target tracking, Motion recognition, and Video stream output
- Pipelining the entire process to 4 separate threads at different fps, similar to CPU pipelining, with a common frame queue between threads
- The pipelining dramatically reduce waiting times
- Ensure the smoothness of the output video, while reducing the fps requirement of the inference process
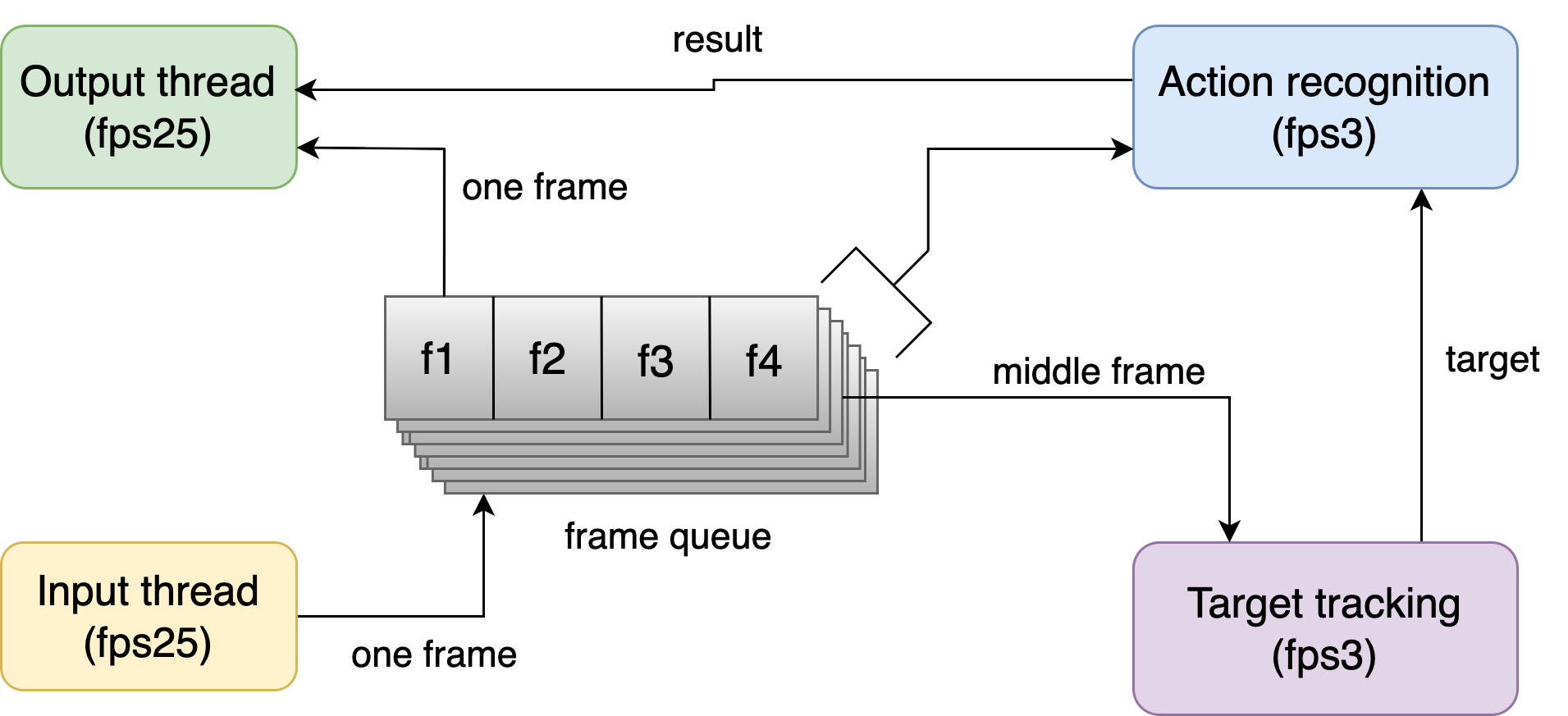
- Space for time, ensuring speed of inference
- In the target tracking stage, the real-time frames of all views are stacked to obtain a (n_imgs * img_shape) matrix as input, the model only does forward inference once, and in the inference, all images are predicted in parallel, so the impact of n_imgs (number of views) on the processing time is negligible
- Similarly, in the action recognition stage, all cropped_clips are stacked to obtain an input matrix of (n_clips * clip_shape), only one forward inference is made, and all clips are predicted in parallel, so the n_clips (number of tracking targets) do not affect on the processing time
What if the input streams of different views are not synchronized?
- Reasons
- The reason for the out-of-sync stream is the inconsistent time delay from different viewpoints, the OpenCV buffer causes the time delay, and the buffer can avoid the lag caused by network fluctuations
- However, due to the different order of TCP connection establishment in different views, the effective length of other buffers is not the same, thus creating the problem of out-of-sync stream
- Solutions
- Create a queue of length ten as a buffer for each viewpoint, read the latest OpenCV frames, and insert them into the queue
- When all queues are full, read each queue synchronously at fps 25
- This preserves the original function of the buffer while synchronizing the time delay and ensuring the consistency of the input view streams
| Out-of-sync input | Synchronized input |
|---|---|
 |
 |
How is the output video stream transmitted in real-time?
- Create a pipeline between python and FFmpeg via the subprocess module
- Python writes the inference result to image frames at a fixed fps and then puts them into the pipeline
- FFmpeg receives the image frames and encodes them using H.264
- Compared to the MPEG4 encoding method, H.264 is more efficient, ensuring clarity with a smaller data volume
- FFmpeg sends the encoded data to DarwinStreamingServer (a live streaming server program), which streams live video in the RTSP protocol
