Background and Purpose
What is AI-assisted medical diagnosis?
- After a patient’s x-ray is taken, AI algorithms will analyze the image to assist the doctor in making a medical diagnosis, including
- Automatically segment different organ regions and accurately calculate proportions or angles
- Identify potential lesions based on different disease characteristics
- Automatic generation of structured diagnostic reports after the doctor reviews the diagnostic results
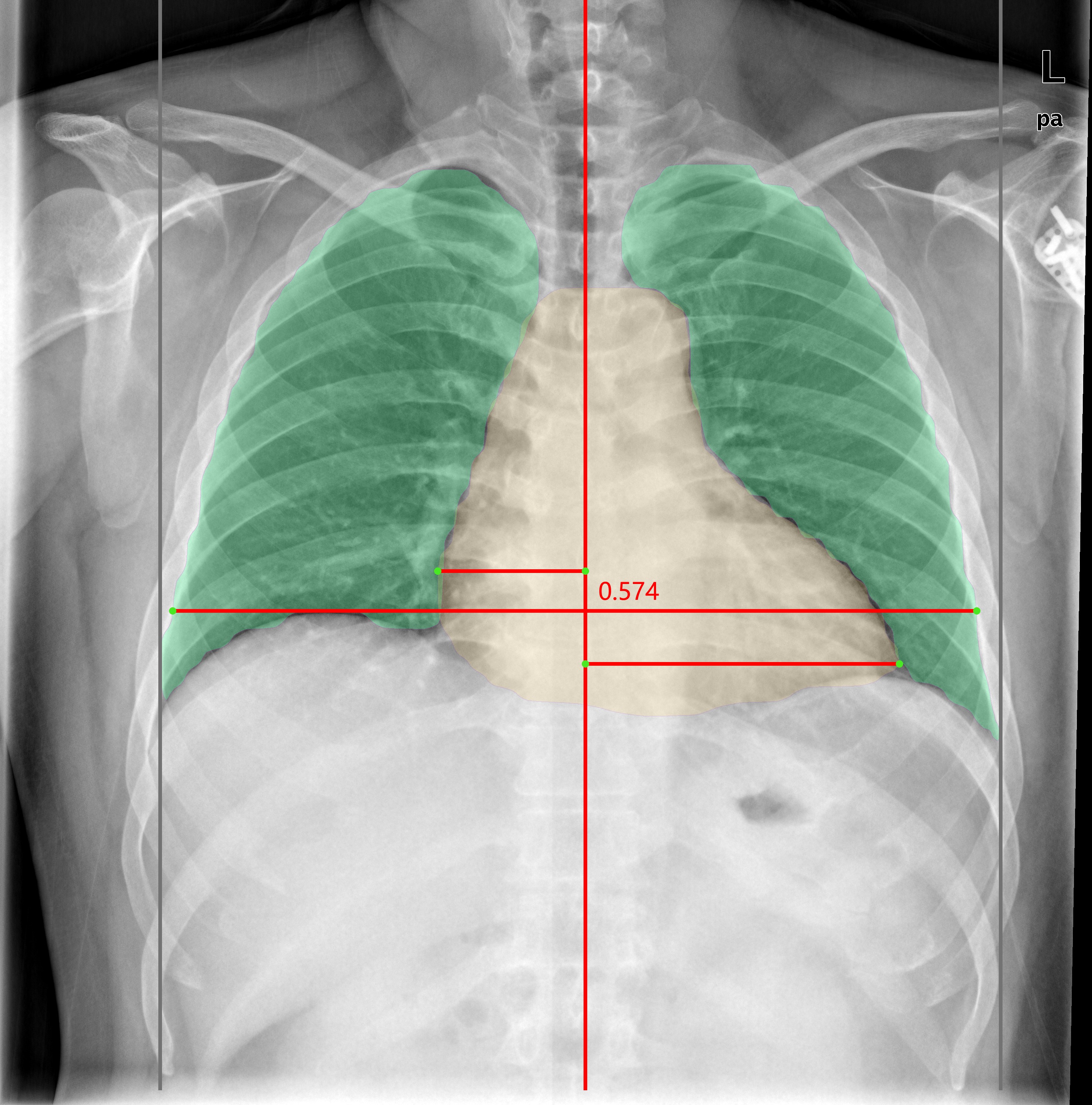
| Scoliosis | Enlarged heart shadow | Pulmonary nodule |
|---|---|---|
 |
 |
 |
Why do we need AI-assisted diagnosis?
- Improve efficiency
- According to experience, it takes 3-5 minutes for a doctor to complete a manual diagnosis. Still, the AI algorithm can give the preliminary diagnosis result in 10 seconds, and it takes less than 1 minute for the doctor to review the result and give the diagnosis report, significantly improving efficiency.
- Risk Warning
- During busy hospital hours, the number of doctors available may be insufficient to view the results immediately, resulting in a buildup of x-ray images. Some diseases (e.g., severe emphysema) are time-sensitive and require immediate surgical treatment upon detection. Otherwise, they may be life-threatening.
- AI-assisted diagnosis can give all patients’ initial diagnosis results in real-time and prioritize them according to their conditions, with more severe conditions being given to doctors preferentially and very serious conditions being alerted to doctors for immediate attention
- Supplementing medical resources in remote areas
- Teaching use
Overview of The Process
Demo

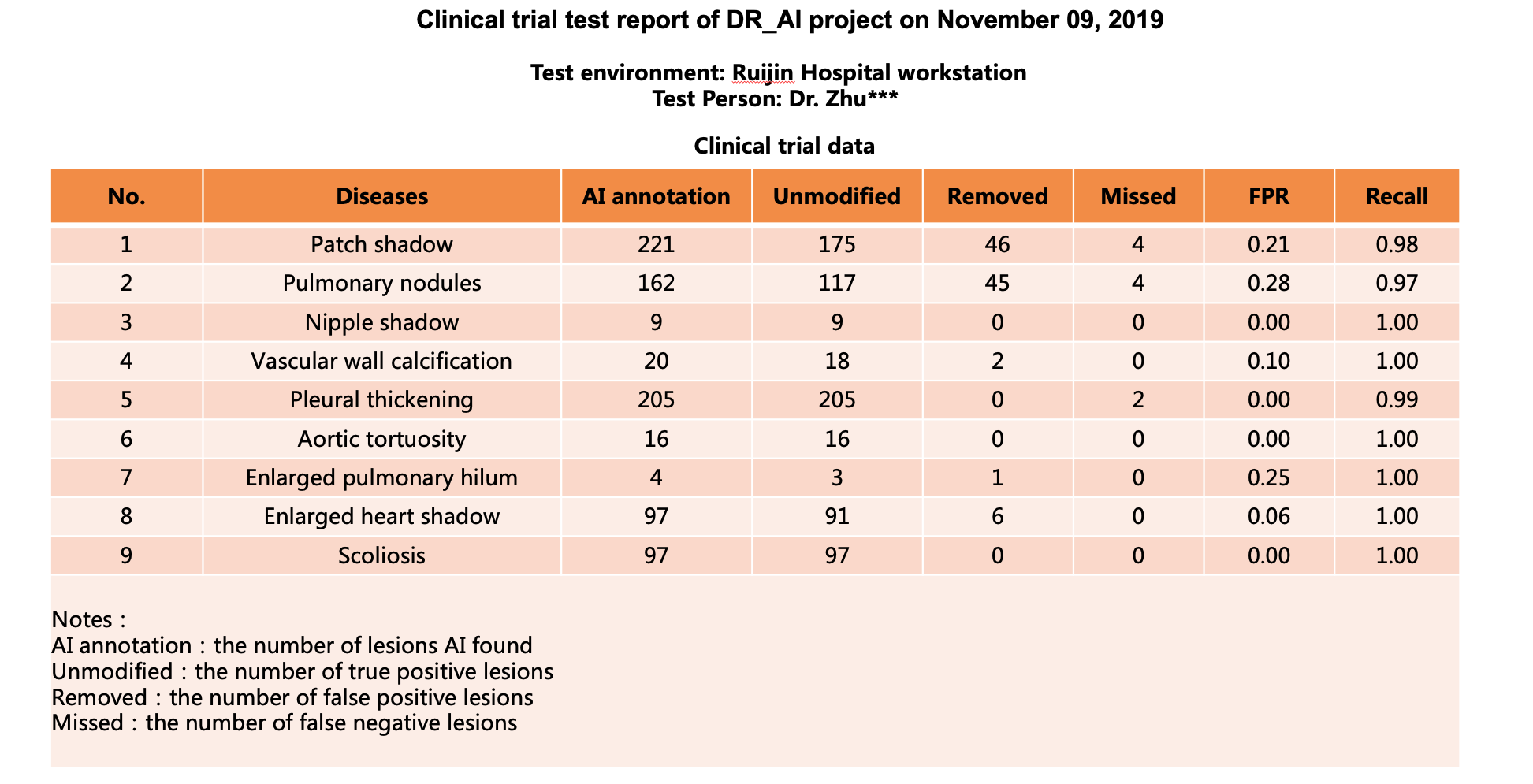
Test Results
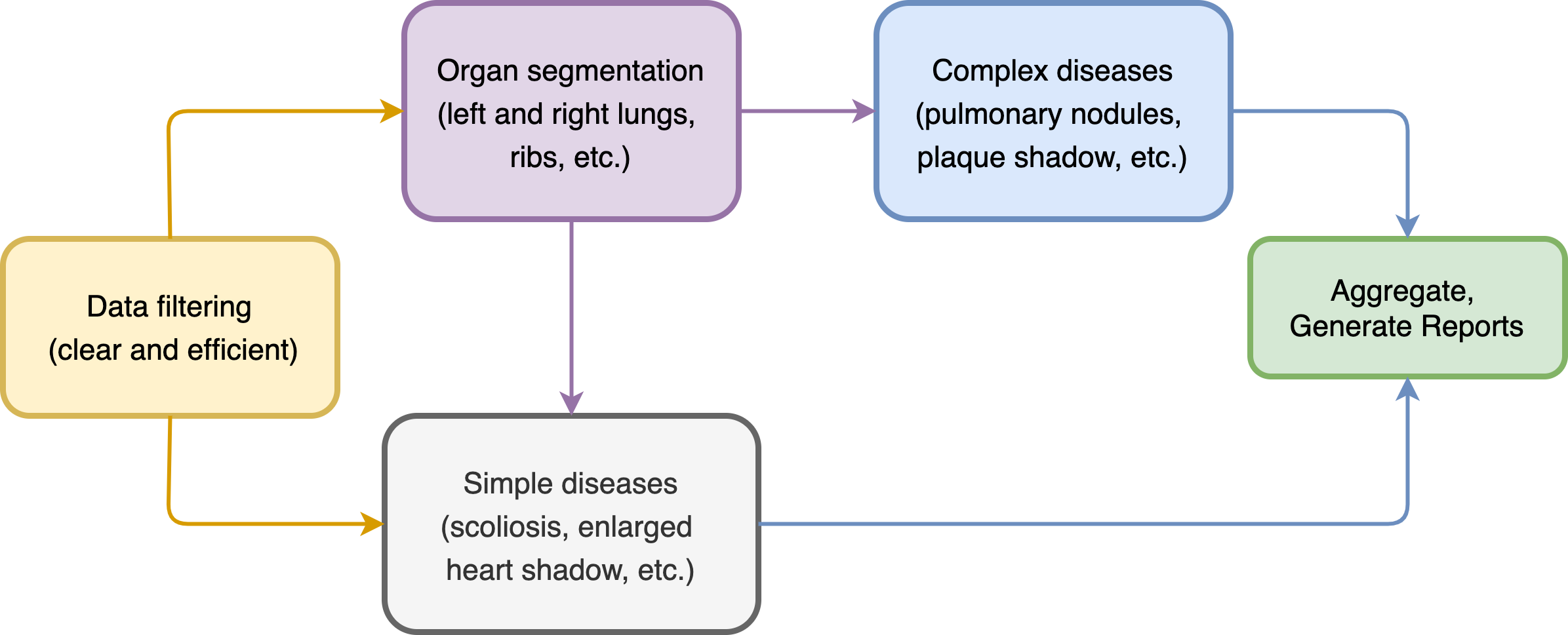
What is the structure of the whole process?
- Data filtering first to make sure the input images are clear and valid
- Then the organ regions were segmented, including the spine, left and right lungs, ribs, etc.
- For simple diseases, just input the original image or the segmented result for classification
- For complex diseases, customized object detection or classification model is required
- Finally, results are aggregated and case reports are generated
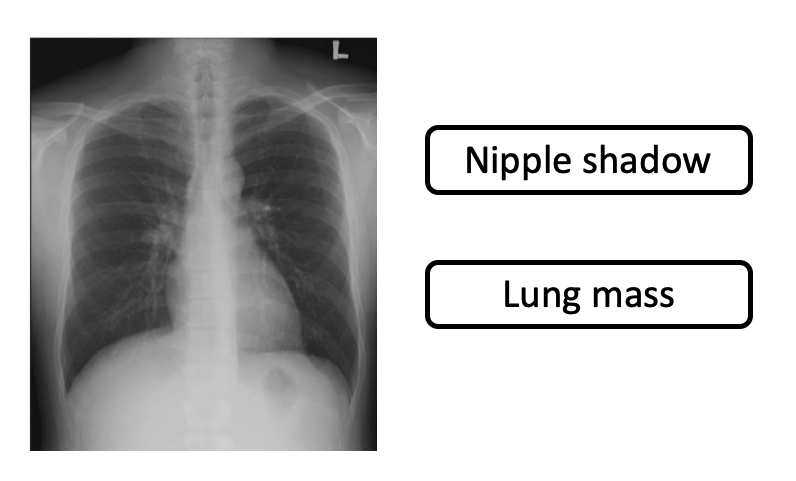
Challenges - Data Preparation
How does the training data been prepared?
- Surveyed public datasets includes ChestX-ray14(2017)、CheXpert(2019)、MIMIC-CXR(2019), etc.
- Some problems with public datasets: incomplete disease types, inconsistent labeling methods, poor labeling quality, differences in the definition of lesions between domestic and foreign medical communities, etc.
- There are still many questions about the accuracy of public datasets, such as question one, question two, challenge three, etc.
| Annotation of public datasets | Expected annotation |
|---|---|
 |
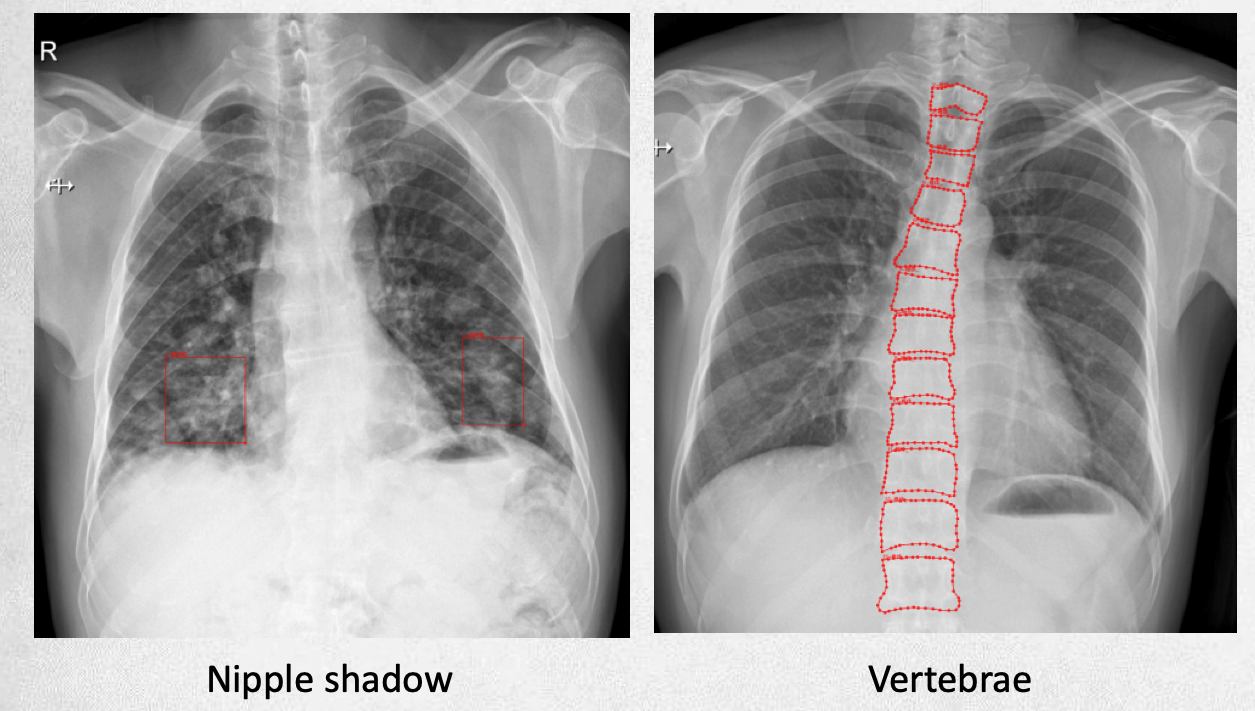 |
- To comply with the domestic standard and to standardize disease species and labeling methods, it was decided to create a self-made dataset
- In cooperation with Ruijin Hospital of Shanghai Jiao Tong University (Triple-A), there are 180,000 original radiographs and corresponding case reports in the database, and 153,000 validity data were obtained after in-hospital desensitization and cleaning.
- The chief radiology physician of Ruijin Hospital’s radiology department was in charge of the annotation and was responsible for the annotation results.
- We built the annotation system and cleaned the data, obtained 34,000 precision labeled data, and built the Ruijin Hospital DR dataset (not open source) in the end
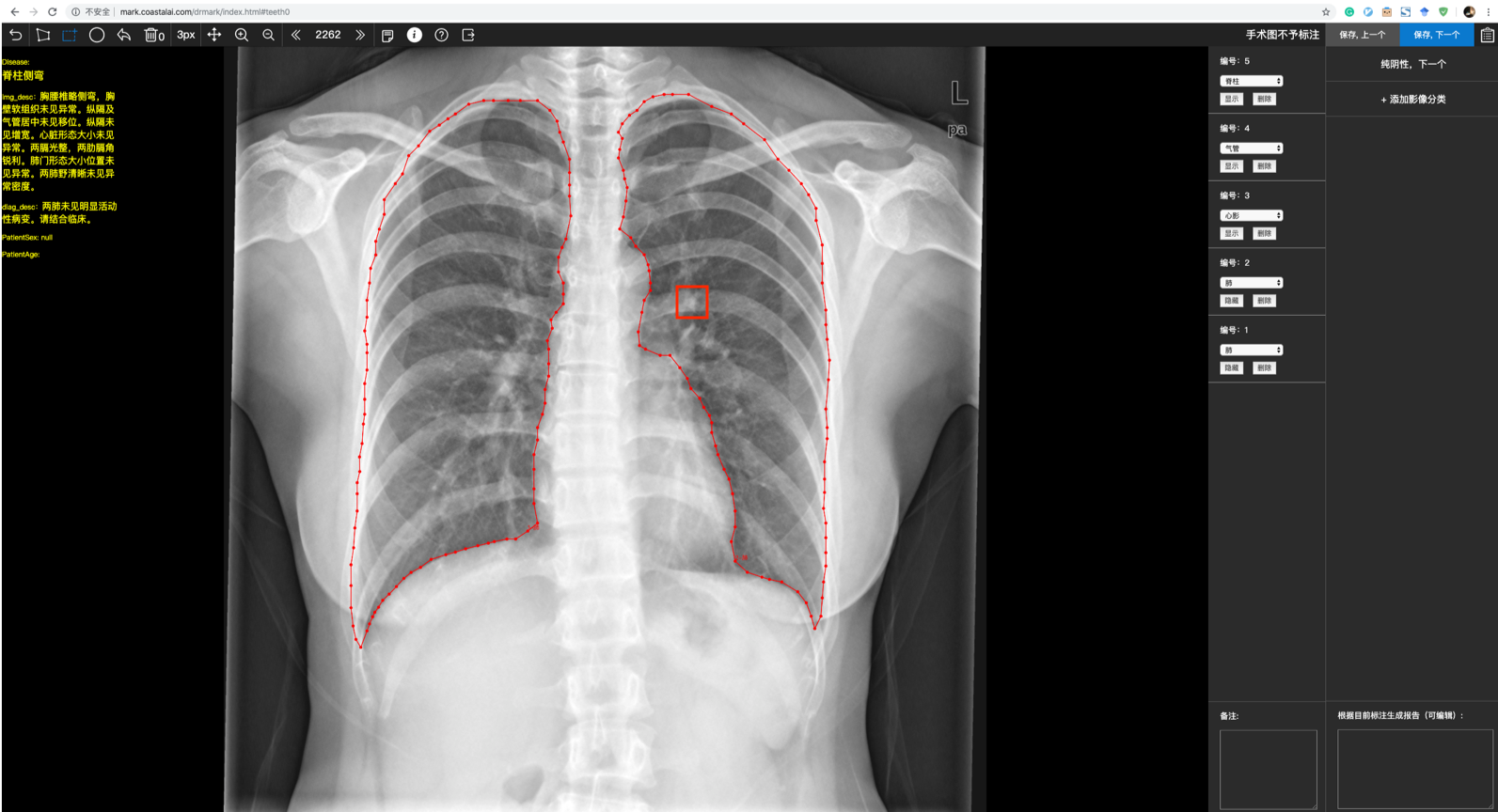
- Data Annotation
- Development of the annotation system
- Segment the organ area and label the lesion type and location
- Both rectangular box and polygon labeling are used
- Cost Control
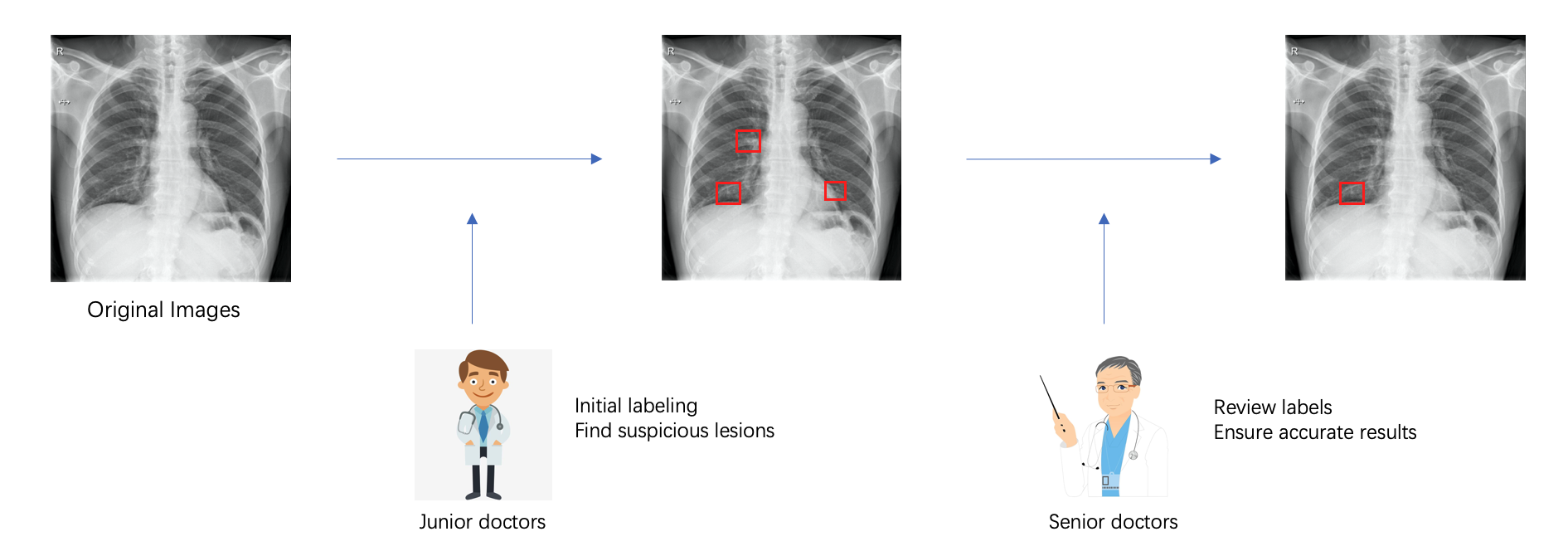
- Professional datasets are very expensive to produce, especially for physician labeling, averaging 40RMB per image
- Establishing a two-stage annotation mechanism, in which junior physicians label first and senior physicians review. Using this mechanism, we reduced costs and ensured the accuracy of results at the same time
- Except for the two-stage mechanism, we also labeled according to demand: some models need a small amount of data to meet the requirements, while models that do not work well were supplied with additional data
How is the data pre-processed?
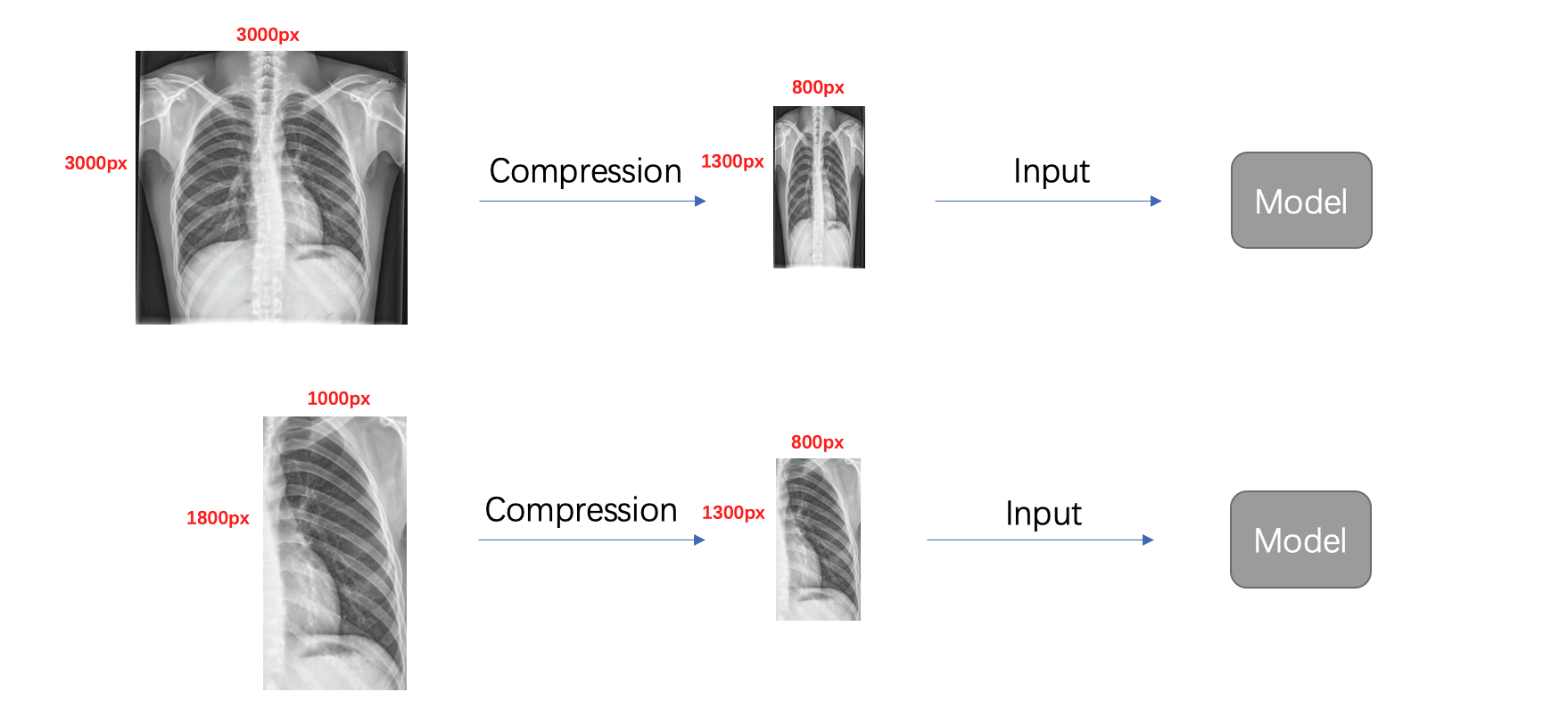
- Cropping
- Different diseases have different appearing regions, e.g., pulmonary nodules only appear in both lungs, so cutting out the lung region and analyzing it separately has a lot of advantages:
- More effective information can be retained after image compression to improve recall
- It can remove irrelevant information and reduce the false positive rate
- Different diseases have different appearing regions, e.g., pulmonary nodules only appear in both lungs, so cutting out the lung region and analyzing it separately has a lot of advantages:
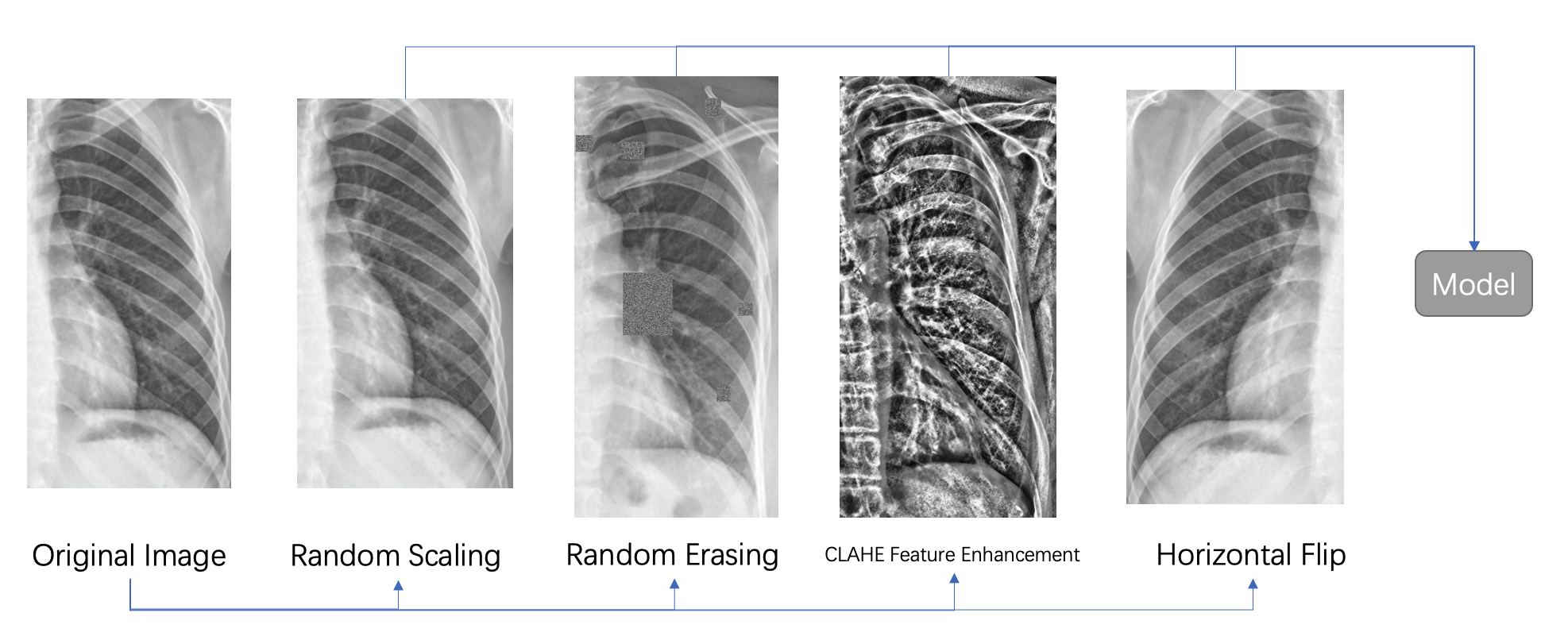
- Data Enhancement
- Random scaling, random erasing, horizontal flipping, and other standard data enhancement methods
- CLAHE feature enhancement
- CLAHE (Contrast Limited Adaptive Histogram Equalization) is a histogram equalization algorithm based on the idea of chunking, which is widely used for data enhancement.
- We observed that CLAHE processing can significantly affect the contrast of bones on X-ray chest films, for example, the contrast of marginal features such as vertebrae and ribs is stronger
Challenges - Algorithm Development
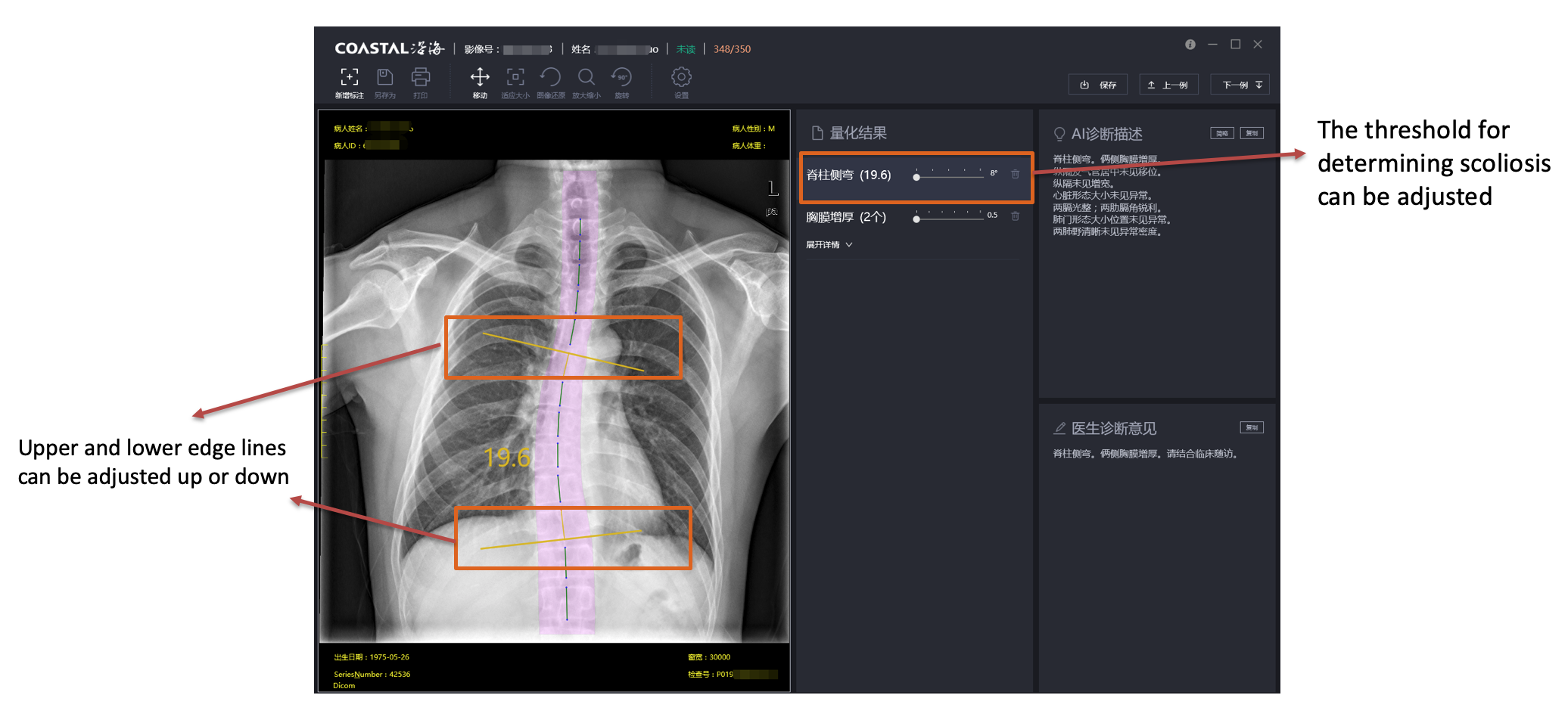
How is scoliosis determined?
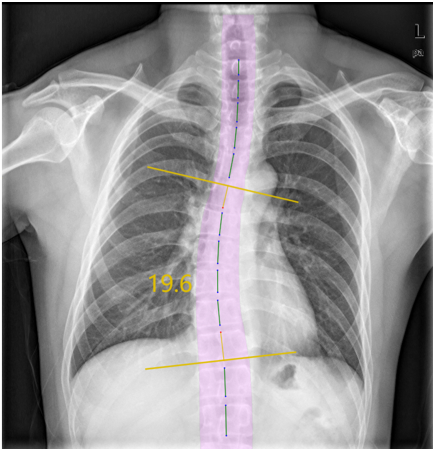
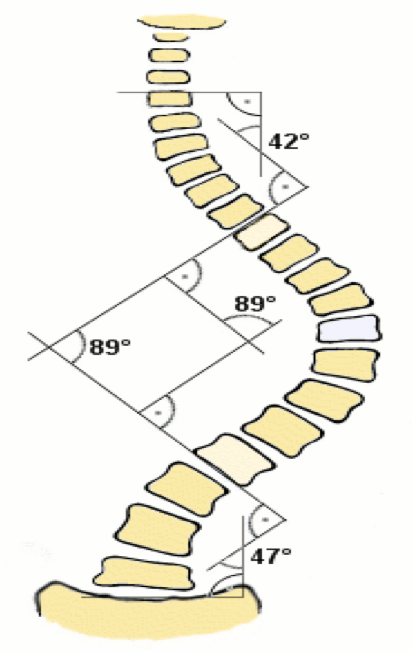
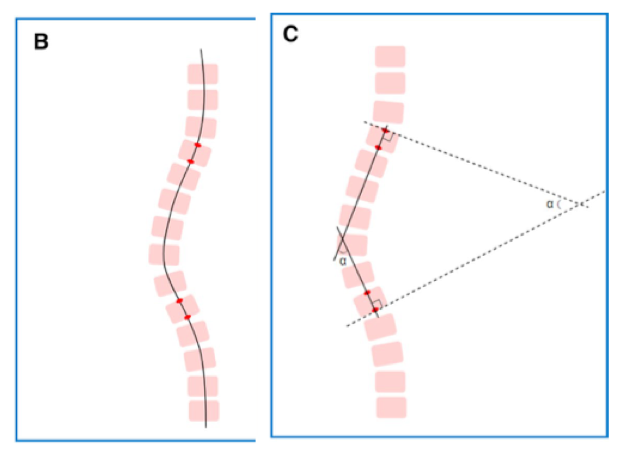
- Cobb angle and its definition
- First, find the two vertebrae that cause the maximum angle, then extend the upper edge of the upper vertebrae and the lower edge of the lower vertebrae, and finally, the angle of the vertical line between the two extensions is the Cobb angle (equal to the angle between the two extensions)
- The Cobb angle is an essential basis for determining scoliosis. Usually, a Cobb angle greater than 10 degrees will be defined as scoliosis
| Definition of Cobb angle | Original image | CLAHE Data Enhancement |
|---|---|---|
 |
 |
 |
- Processing Flow
- Original image –> CLAHE data enhancement –> MaskRCNN segmentation –> Outer edge point conversion –> Post processing
| MaskRCNN segmentation | Outer edge point conversion | Post processing |
|---|---|---|
 |
 |
 |
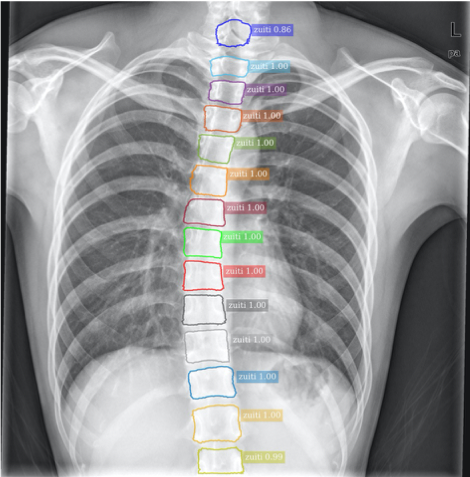
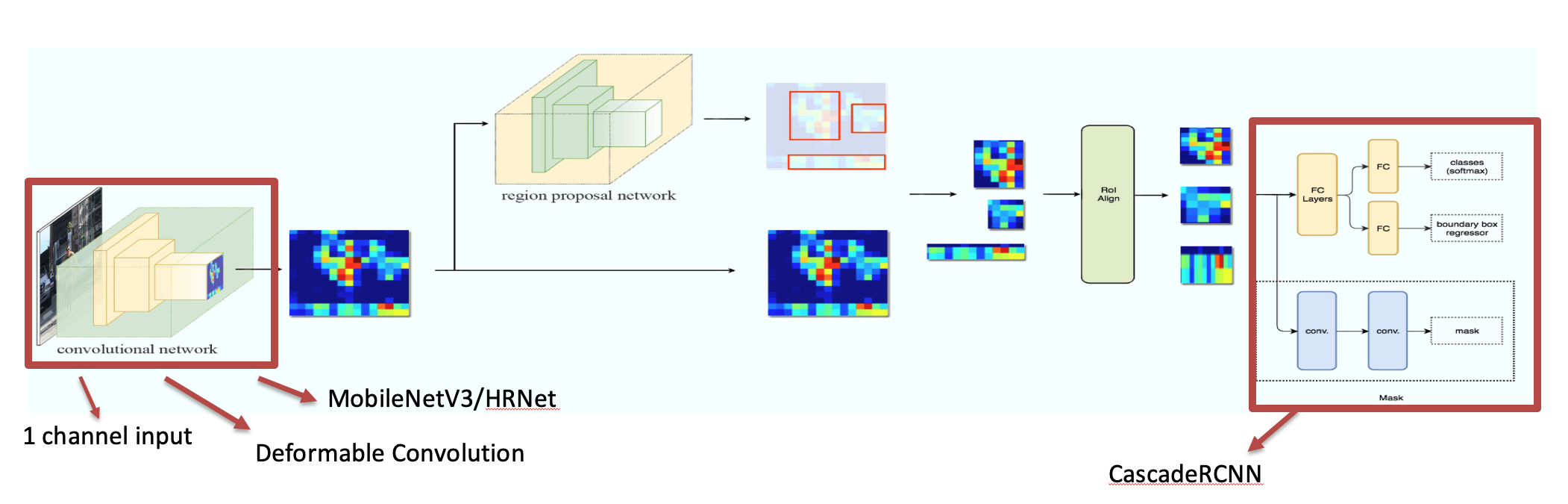
- Train MaskRCNN segmentation model
- MaskRCNN is a two-stage instance segmentation framework based on RPN to filter the foreground and background, where the foreground refers to the valuable target of the image, and then classifies, locates, and segments the filtered foreground information.
- The convolution method was replaced with deformable convolution
- Use advanced HRNet as the backbone
- output using CascadeRCNN
- Post-processing
- The intervertebral angle is the angle between the superior border of the upper vertebral body and the inferior border of the lower vertebral body
- Calculate the angle between each vertebra and all other vertebrae; the largest angle is the cobb angle
- Evaluation of results
- Found 97 scoliosis cases in 1000 test images; all of them are retained by doctors, 0 added, 100% recall rate, 0% false positive rate
- Two hundred forty-eight images were selected and manually labeled by two doctors, with an average absolute error of 2.2 degrees between doctors and 3.32 degrees between the algorithm and the doctors.
- Results Show
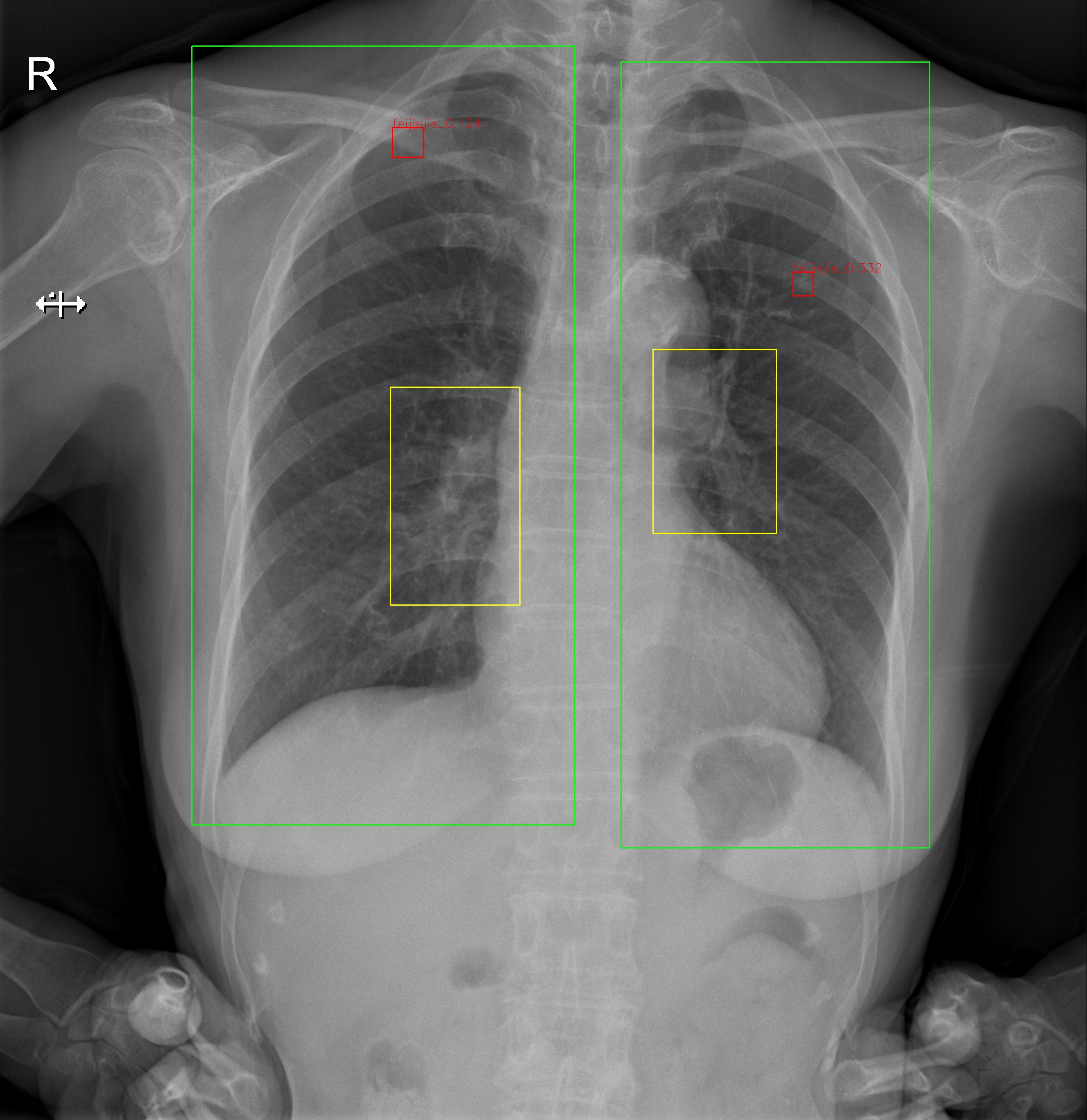
How is the pulmonary nodule determined?
- Pulmonary nodule appears as round, white shadows on chest X-rays, usually between 5 mm and 30 mm in size, and may be a precursor to cancer.
- Processing Flow
- Cropped unilateral lung image –> FasterRCNN object detection –> crop out –> classification –> results
- Training FasterRCNN object detection model
- The overall architecture is basically the same as MaskRCNN
- MobileNetV3 is used as the backbone, which requires less computing power and infers faster than HRNet
| Unilateral lung images | Object detection results | classification |
|---|---|---|
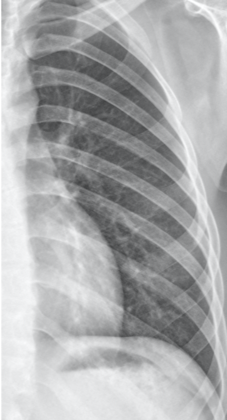 |
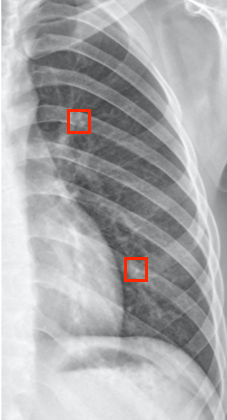 |
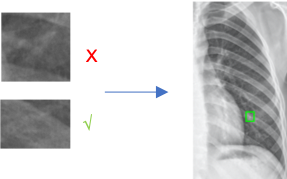 |
Why do we need to train a separate classification model?
- Question
- It was found that the false positive rate of FasterRCNN was very high (>60%) when high recall (98%) was guaranteed, and the false positive rate only decreased slightly when trying to optimize the network structure or supplement the data.
- Conjecture
- There’s a loss of information during convolution because of the limitation of the feature extraction network itself
- There’s a loss of information about the correlation with surroundings because FasterRCNN’s classifier can only classify the recommended region limited by RPN
- Analysis
- The object detection of an ordinary object which has distinctive features is not easily confused with other objects, and as an independent object, it is often distinct from the background, which leads to a partial loss of information in the convolution process and the loss of information about the surrounding association has little effect on the results
- The determination process of pulmonary nodules is different from that of ordinary objects, and the partial loss of information during convolution and the loss of peripheral correlation information may cause it to be indistinguishable from other similar structures with too little difference, which leads to a consistent failure to reduce the false positive rate.
- Evidence
- In determining pulmonary nodules, the consulting physician will not only observe the appearance of the suspicious area but also observe the texture of the target, the density, and the direction of the surrounding blood vessels and even combine the information with the patient’s past cases and lifestyle.
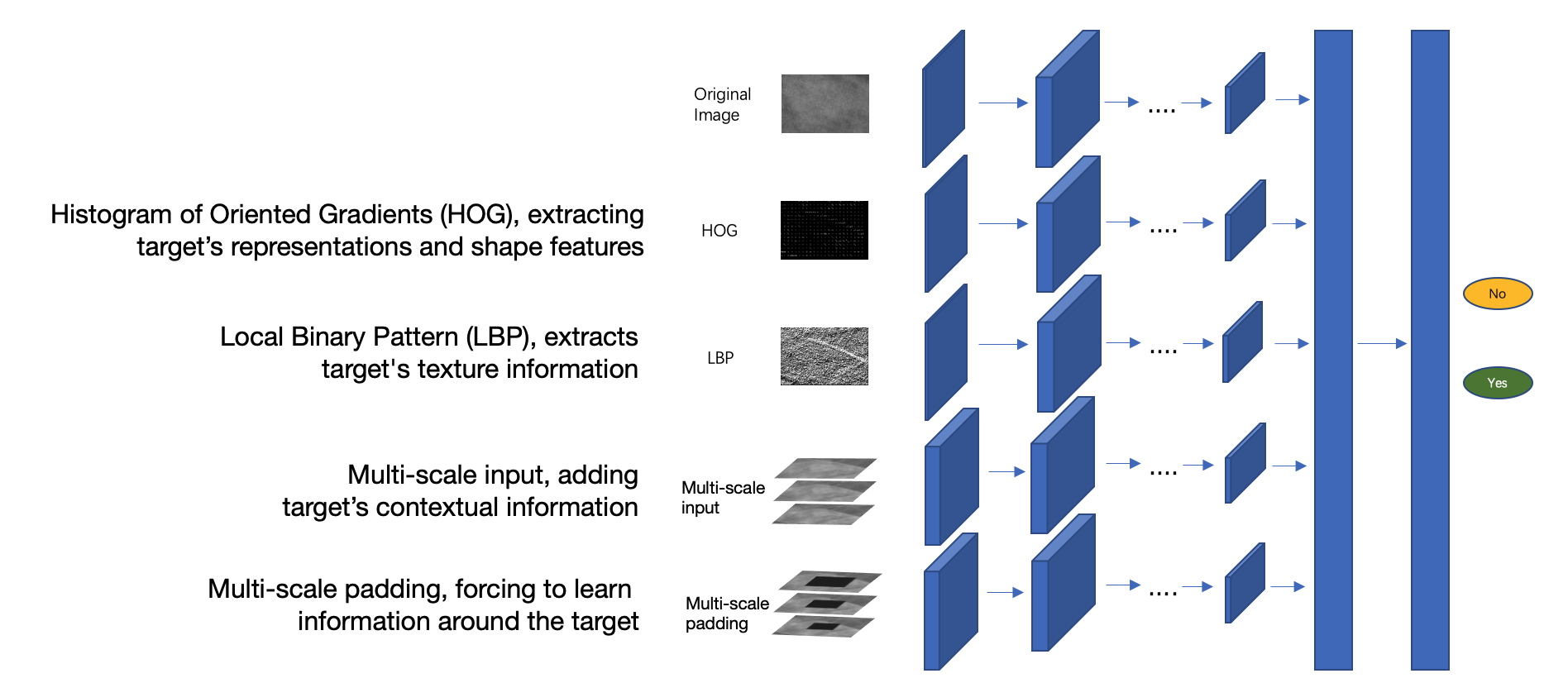
- Solutions
- Customized classification network, accepting multi-dimensional input, as a complement to FasterRCNN
- Simulate the doctor’s diagnosis method, extract geometric, textural, and contextual information of the suspected area, and put it into the model
- FasterRCNN as “primary filtering”, the classification model focuses on reducing the false positive rate
- Evaluation of results
- Found 162 suspected pulmonary nodules in 1000 test images, with 117 of them retained by doctors and four new ones added
- 97% recall rate, 28% false positive rate, a significant decrease in false positive rate
Notes
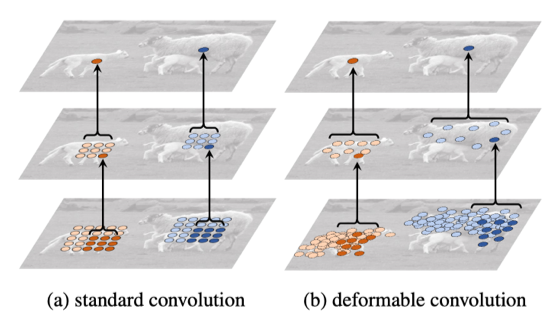
Deformable Convolutional Networks
- Unlike traditional fixed-size convolution kernels, the size of the deformable filter changes according to the feature information.
- Stronger ability to model the deformation and scale of objects
- The perceptual field is much larger than normal convolution filters
- More sensitive to the shape and size of the target
HRNet
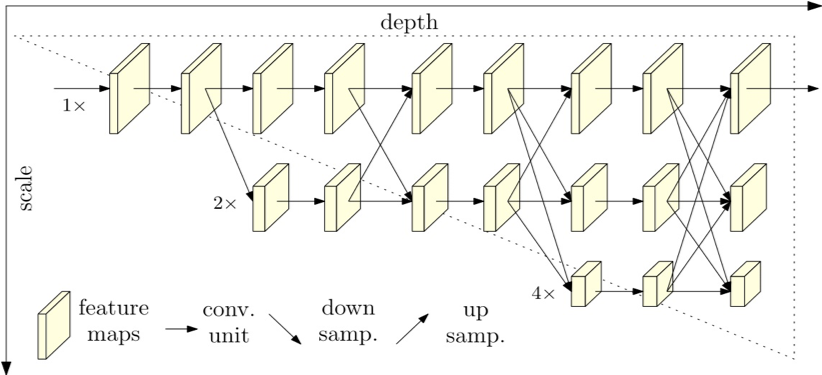
- Unlike ResNet, which extracts features from high resolution to low resolution and low dimension to high latitude, HRNet can maintain high-resolution representation throughout the process. Specifically designed to improve the accuracy of segmentation
- Considering that our X-ray image size is usually above 2000*2000, in addition to the input resize adjustment, the entire feature extractor maintains a high-resolution representation can improve the accuracy of segmentation
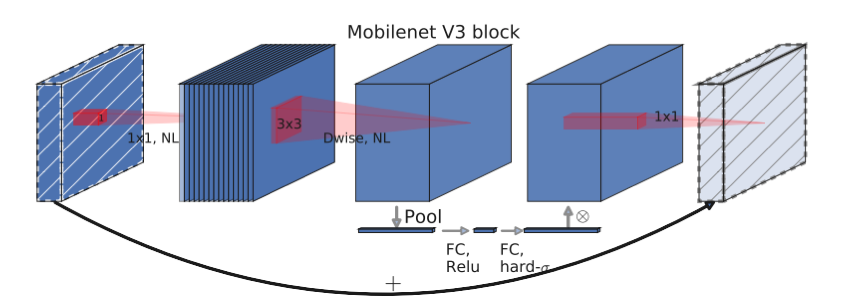
MobileNet
- By applying deep separable convolution, inverse residual structure, attention mechanism, and other optimizations, the computational effort of feature extraction is significantly reduced while ensuring accuracy, and the performance is good enough for simple targets (e.g., lung region) while lowering the GPU memory usage.
CascadeRCNN
- The trainer’s performance is best when the threshold value of the proposal itself and the threshold value used for training the trainer are close to each other. The CascadeRCNN uses a 3-layer iterative box regression, which can improve the detection effect