背景和目的
什么是活体检测?
- 活体检测是判断图像中的人脸是否为真人(活体)的一项服务
- 在进行一些监管严格的业务时, 我们需要验证操作者是否真的是本人, 因此除了进行人脸比对, 往往还需要进行 “是否是真人(活体)” 的判断, 即活体检测
- 黑产行业常常利用伪造的人脸(非活体)试图通过验证, 一些非活体攻击举例
屏幕 照片 裁剪纸 面具 



为什么需要自研活体检测?
- 公司多项业务需要用户实名认证且要求本人操作, 每天业务量巨大, 随着业务扩张需求持续增长
- 公司目前使用腾讯、商汤等公司提供的活体检测接口, 付费调用, 每年为此支付高额费用
- 自研活体检测服务的优势
- 完全或部分替代第三方接口, 可以节约支出
- 加入公司打造的SaaS平台, 对外商用, 可以带来收入
成果
产品落地了吗, 效果怎么样?
- 已经接入公司旗下全部APP, 替换第三方接口
- 上线至移卡云(SaaS平台), 对外商用
- 演示视频
产品有哪些奖项和成果?
- 公司月度最佳项目
- 专利: 《虚假人脸的检测方法、终端设备及计算机可读存储介质》
- 第一作者
- 专利号: CN113297960A
处理思路
活体检测的处理流程是怎样的?
- 如图所示, 一共三个步骤: 人脸质量检测、动作活体检测、静默活体检测, 分别在移动端和服务器端完成

- 流程图
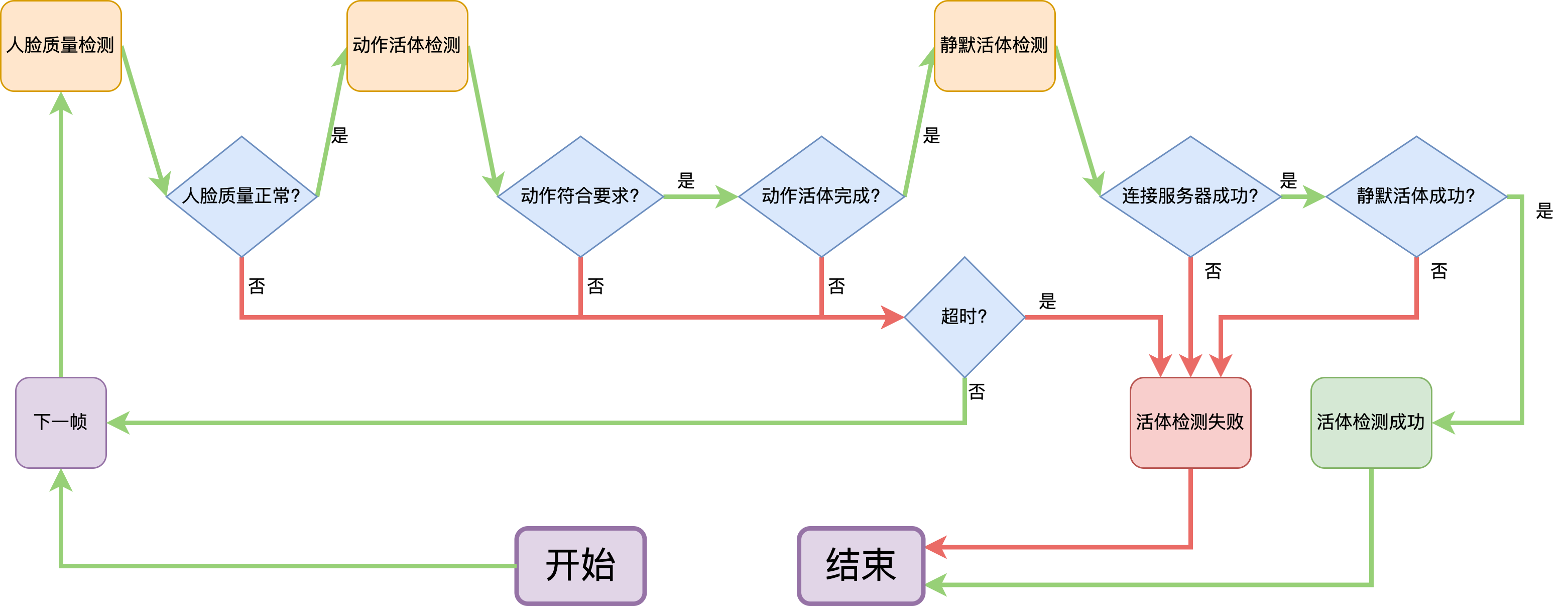
人脸质量、动作活体、静默活体检测是什么意思?
- 人脸质量: 确保图片无抖动、有人脸、光照正常
- 动作活体: 指定张嘴、眨眼、转头等随机动作, 若用户能正确完成, 则通过, 否则拦截
- 静默活体: 检测图片的材质, 以及是否有摩尔纹、变形、屏幕边界等攻击特征
人脸质量(❌) 人脸质量(❌) 张嘴动作(❌) 静默活体(❌) 静默活体(✅) 




为什么静默活体要在后台的服务器上完成, 不能放到移动端?
- 要识别摩尔纹、纸张材质、变形等攻击特征, 小模型表现不好, 需要大模型
- 大模型需要较高的算力, 无法部署在移动端
为什么要分成三步, 不能一步完成?
- 人脸质量检测
- 保证图像光照正常、无抖动, 排除异常情况, 提升后续算法的准确率
- 动作活体检测
- 通过随机动作, 在移动端即可过滤掉大部分攻击(如表情不变的面具), 减轻服务器端压力
遇到的挑战 - 服务器端
怎么确定静默活体解决方案的?
- 技术调研
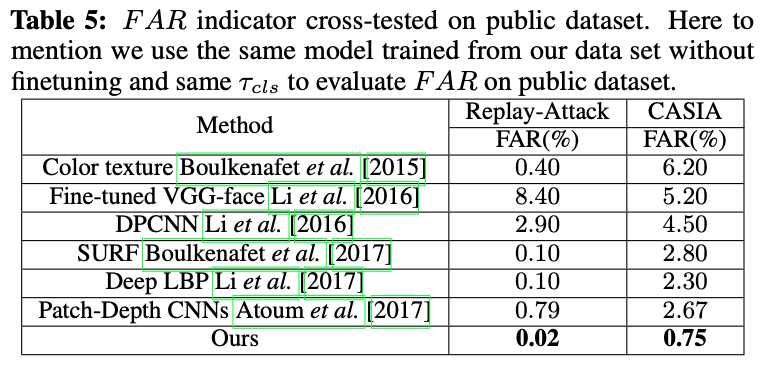
- 评估指标: 误拦率FRR(实际为Real, 误判为Fake)、误过率FAR(实际为Fake, 误判为Real)、平均值HTER
- Color texture(传统图像算法最好): 2~3%HTER, 其余传统算法一般为14~20%HTER
- CVPR2019、2020: 1~2%HTER, 其中腾讯三色光1.24%HTER
- 数据分布差异的影响
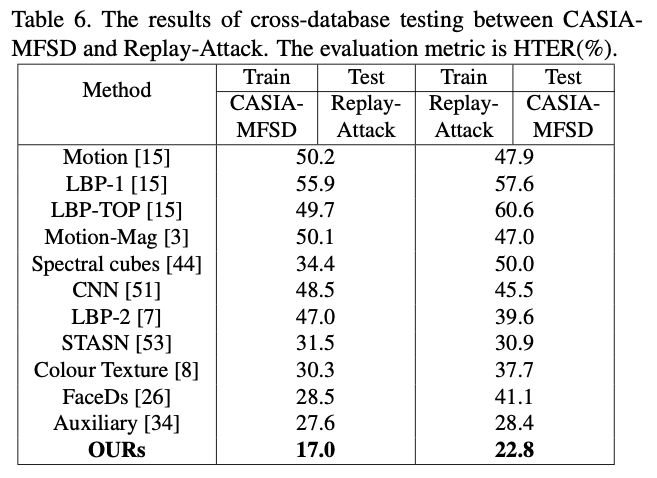
- 通过论文发现, 训练测试同分布的情况, 现有模型都能达到较好的效果, HTER上差别并不大
- 但是训练测试数据分布差异的影响很大. 较差的模型, 在好的数据集上训练的测试结果远远超过较好的模型在差的数据集上训练的测试结果
- 实验
- 尝试多个项目FaceBagNet@CVPR19-2nd、CDCN@CVPR20-1st、SGTD@CVPR20-2nd等, 均放弃, 缺点如下
- 基于binary classification来做的, 效果不好, 放弃
- 需要连续帧信号, 带宽速度对响应时间有较大影响
- 需要DepthLabel辅助, 不好获取, 用PRNet生成的话, 速度较慢
- 计算量太大, Infer速度慢
- 论文使用的数据集分布太单一, 训练出来的模型在我们的真实数据集中表现并不好, HTER>20%
- 对平面欺诈问题效果不错, 但是对3D面具等不适用
- MiniFASNet@MiniVision
- 测试效果不错, 在所有模型中表现最优, 跨数据集结果~10%HTER
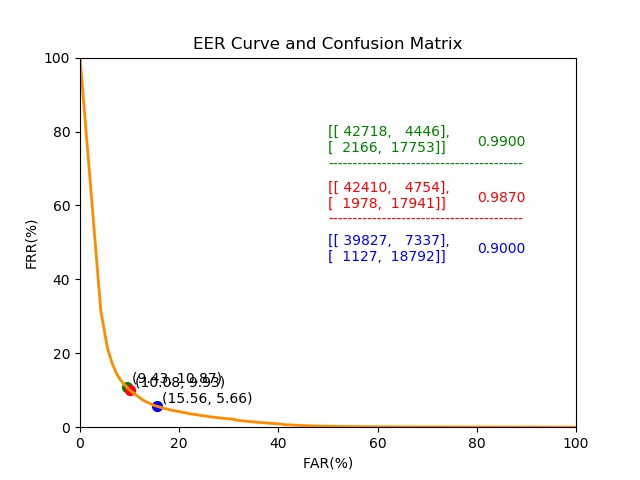
- 测试效果不错, 在所有模型中表现最优, 跨数据集结果~10%HTER
- 尝试多个项目FaceBagNet@CVPR19-2nd、CDCN@CVPR20-1st、SGTD@CVPR20-2nd等, 均放弃, 缺点如下
怎么优化结果?
- 从数据上优化
- 开源数据集: CASIA_FASD、Oulu_npu、LCC等6个开源数据集, 共150万张图片
- 自制数据集: Yeahka_FAS(private), 190万张图片
- 跨分布数据
- Real的分布举例
正常 偏亮 偏暗 背光 模糊 



- Fake的分布举例
屏幕摩尔纹 屏幕反光 屏幕材质 屏幕曝光失真 


照片纸 裁剪纸 面具 3D面具 
- Real的分布举例
- 模型弱点分析, 针对性自制数据集
- 投票机制
- 多个尺度的模型共同投票
Ratio1.0(全脸)模型 Ratio1.5(近景)模型 Ratio2.7(远景)模型 关注脸部细节 关注脸部与背景的过渡 关注背景、边缘等细节 


- 对多帧投票
- 随机动作: 张嘴、眨眼、摇头等动作, 可以增加难度
- 动作可能引起假脸的移动、偏转, 从而露出破绽
- 多个尺度的模型共同投票
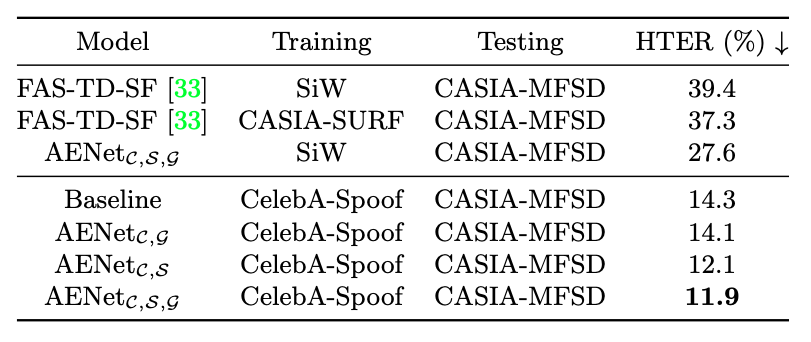
- 引入第三方通道
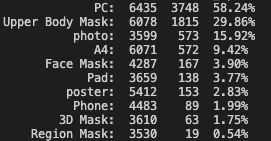
- 移卡通道提高阈值至0.99: 误过率FAR<0.01%, 误拦率FRR~10%
- 对于模型判定为Fake的结果, 送至第三方通道, 用它的结果返回
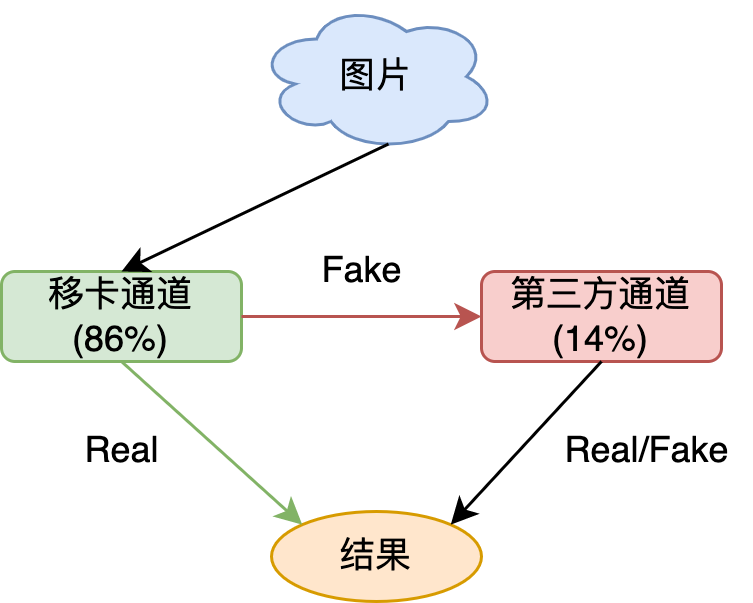
- 最终结果
- 实际为Fake的图片1000张, 全部被拦下, 误过率FAR=0%
- 实际为Real的图片16000张, 误拦率FRR=0.7%, 优于第三方通道
- 第三方通道请求比例减少了86.3%, 举例: 100个请求86.3个可以自己完成, 13.7个仍需请求第三方
误拦率FRR(%) 移卡通道比例(%) 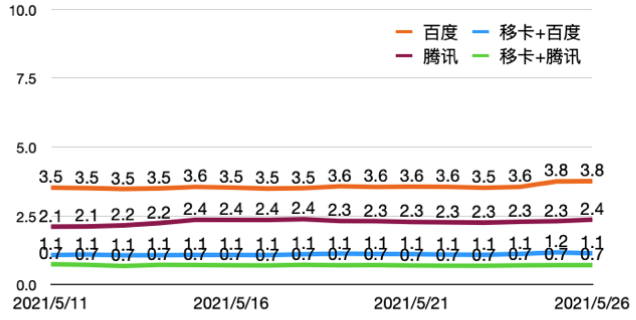
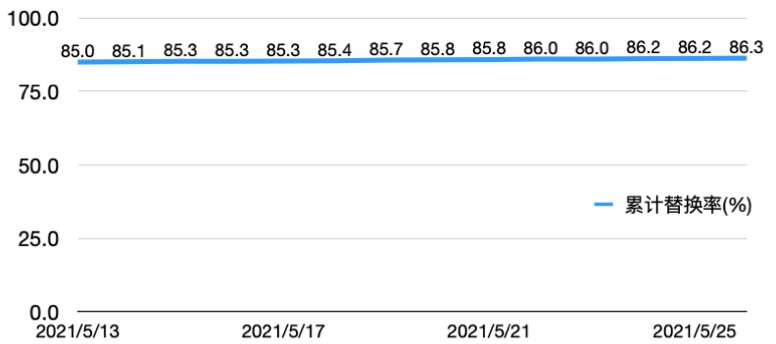
怎么提高服务的稳定性?
- 模块替换
- Ratio1.0+Ratio1.5与Ratio2.7模型
- 如果人脸太近使得Ratio2.7模型无法工作, Ratio1.0+Ratio1.5模型也能返回结果
- 本地通道与第三方通道模块
- 如果本地模型失效, 全部请求转发给第三方通道
- Ratio1.0+Ratio1.5与Ratio2.7模型
- 负载均衡与容灾系统
- 多套系统部署在不同服务器上, 中台控制转发请求, 流量均衡分配给不同的服务器
- 如果某个服务器返回出错/超时, 中台会将其下线, 待修复问题后重新上线
- 如果多台服务器返回出错/超时, 中台关闭服务, 全部请求转发给第三方通道
- 监控
- 用supervisor服务做进程监控, 进程异常退出自动重启
- 定时扫描日志, 出现模块、系统或者服务异常, 发送告警信息
- 定时请求接口, 如果返回结果与预期不一致, 发送告警信息
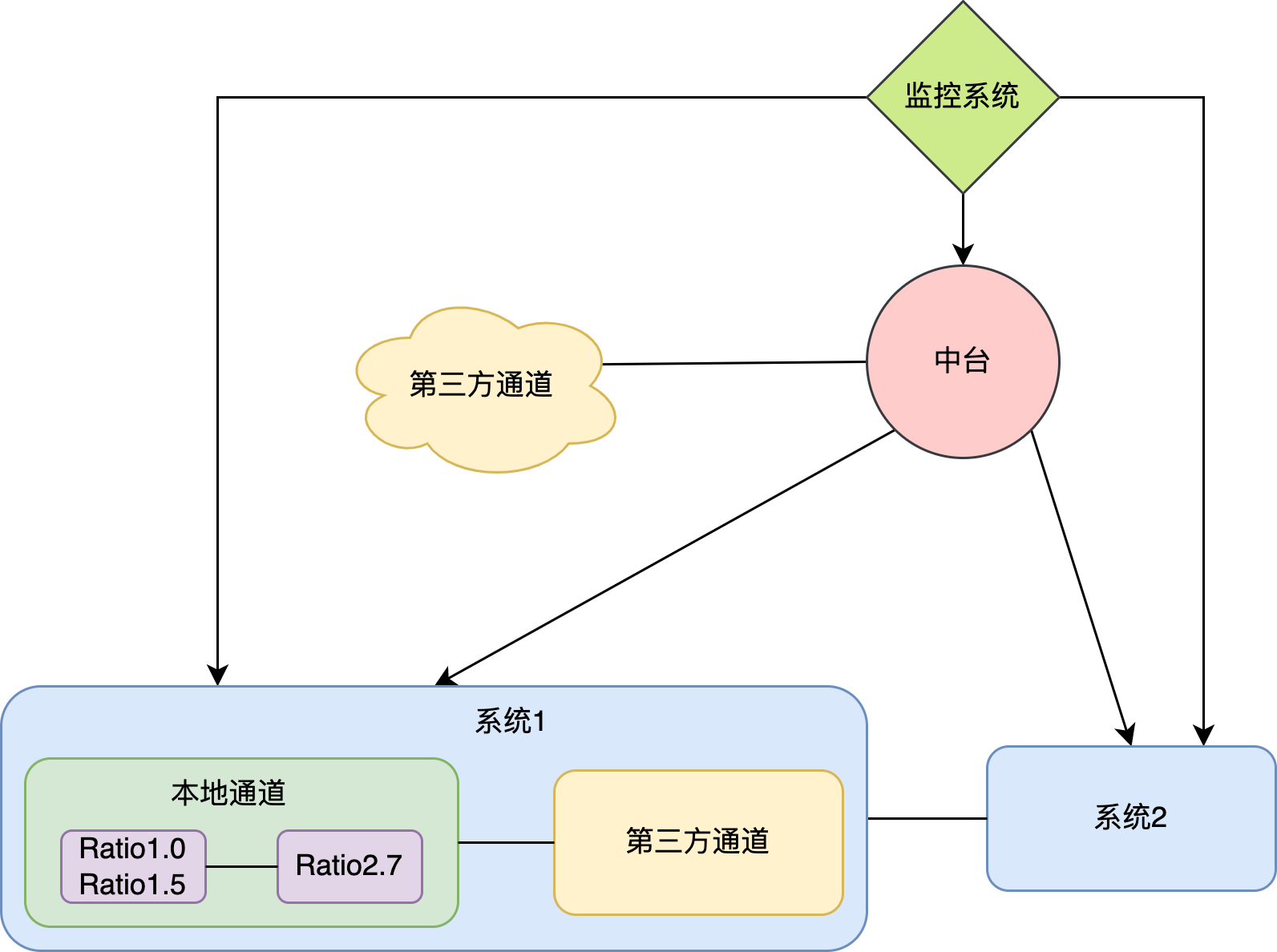
怎么提高服务的并发能力?
- gunicorn启动多进程, 并发接受请求, 平均分配CPU、GPU算力和I/O
- 中台与后台建立TCP长连接传输数据, 避免重复握手
- 缓存数据, 一次写入, 避免重复IO操作
- 锁机制, 保证多进程写日志时操作的原子性
- 减少不必要的计算, 优化速度
遇到的挑战 - 移动端
怎么确定动作活体解决方案的?
- 训练分类模型, 做动作识别
- 缺点
- 增加/减少动作需要重新训练模型
- 人脸差异性, 容易误识别
- 缺点
- 从2D映射到3D, 用2D的关键点恢复其3D坐标, 从而确定动作
- 效果很好, 朝向正确
- 需要关键点数量较多, 计算量大
- 减少关键点数量, 准确度下降

- 猜想通过关键点相对位置可以推测动作
- dlib找到68个关键点, 通过实验验证猜想
- 确定9个关键点, 并给出动作的计算代码
左转头 右转头 低头 张嘴 
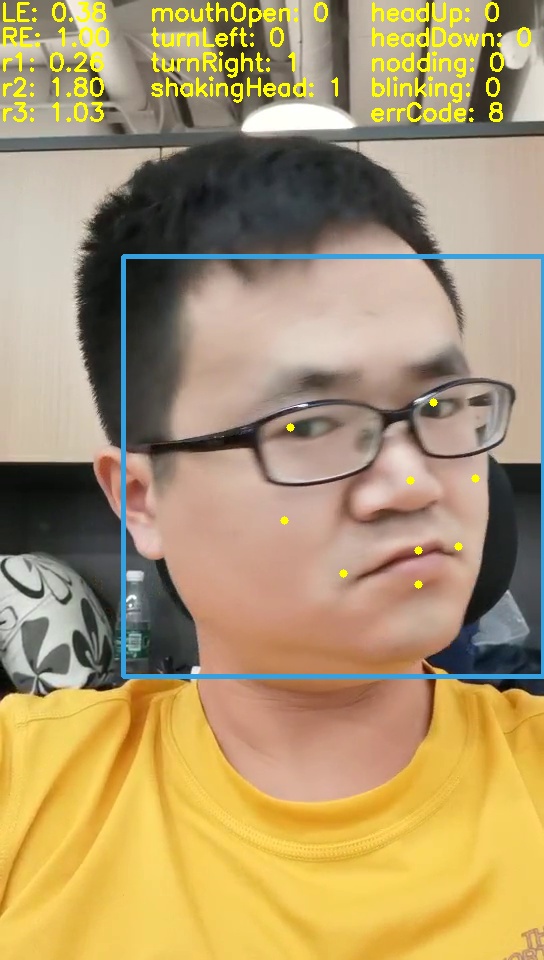
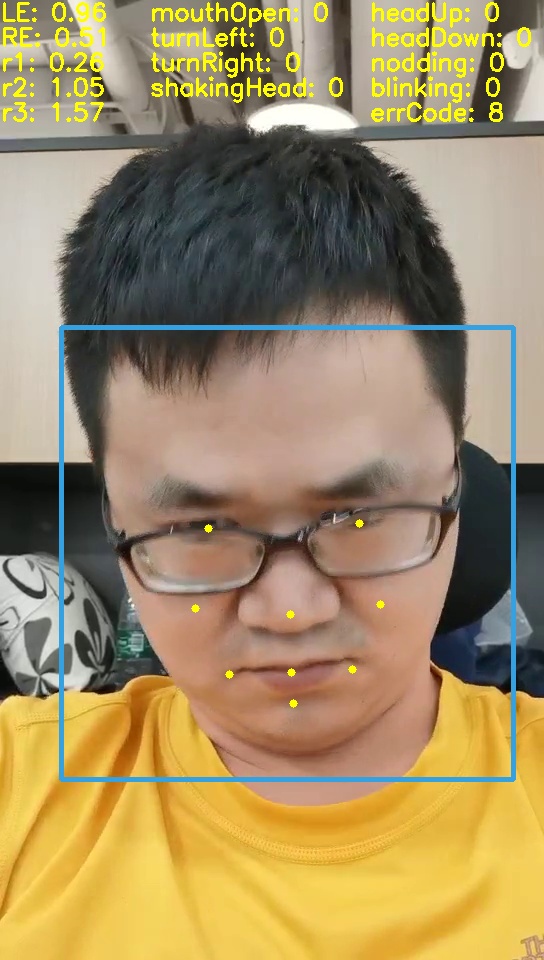
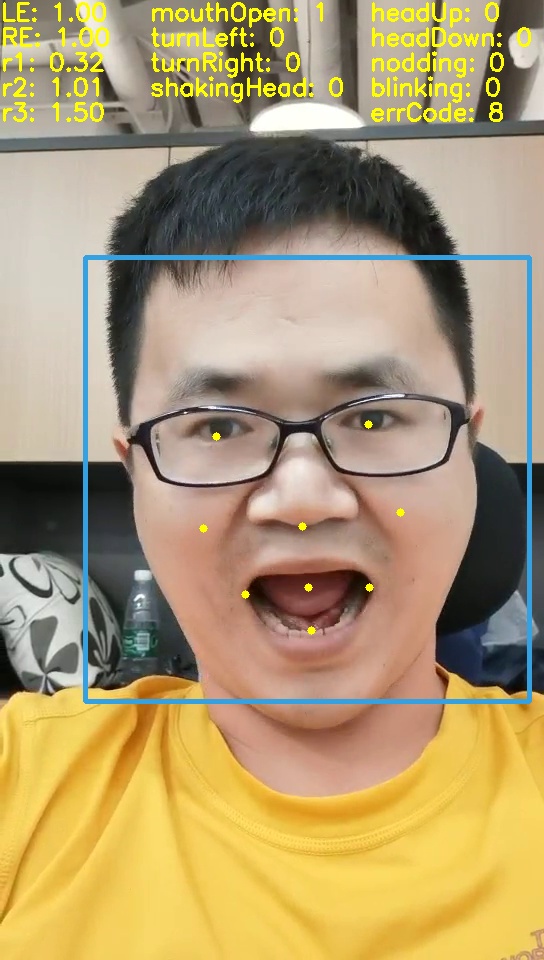
算法上有哪些创新?
- 多步骤合并
- 脸部bbox、脸部关键点、是否闭眼
- 一个模型一步完成, 大大减少推理时间
- 减少不必要的计算
- 丢弃较小的脸部候选框, 同时提升MTCNN三个阶段的阈值
- 这一步可以舍弃那些概率较小的候选框, 减少计算量
- 排除个体差异
- 用多帧平均的方式提高动作识别准确率, 减少误过率
- 计算平均静态脸, 通过与静态脸对比来确定动作, 代替直接根据阈值来确定动作
- 针对性的改进
- 暗光、抖动、失焦都会影响关键点的位置, 也会影响静默活体模型的判断
- 提出人脸质量检测步骤, 先做过滤, 保证图片清晰、明亮
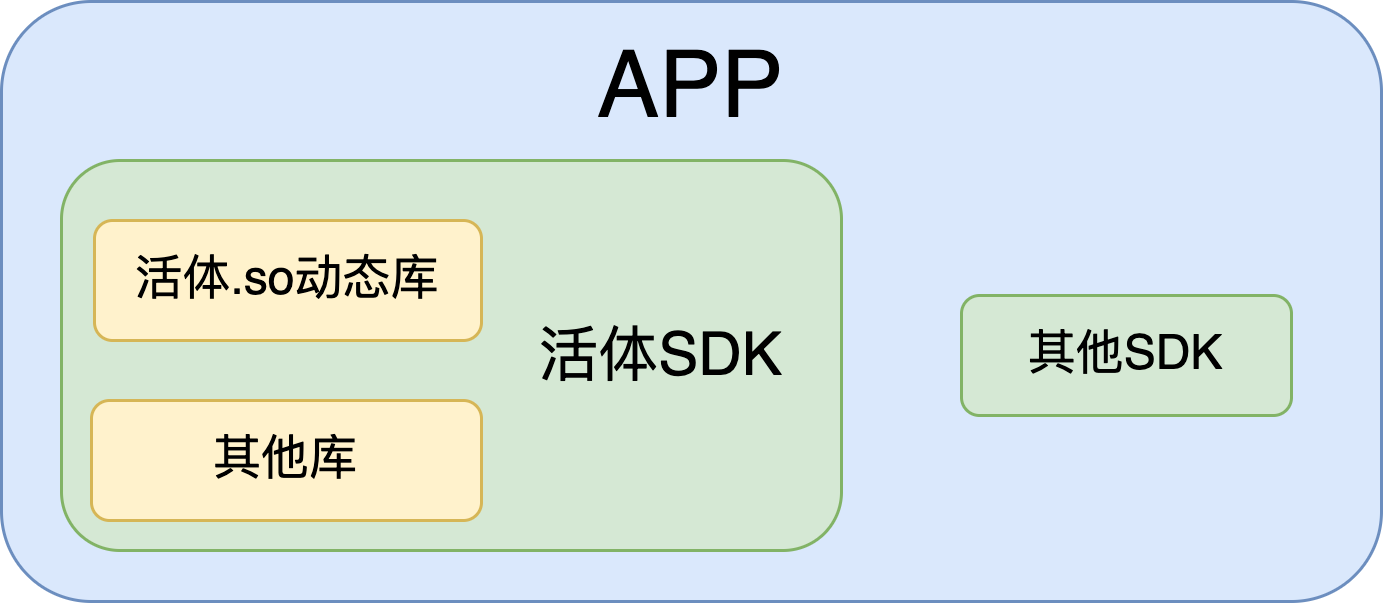
移动端的调用逻辑是怎样的?
- APP —> SDK —> so动态库
- APP在活体检测时直接启动SDK, 然后接受SDK的返回即可, 返回活体通过/不通过
- SDK打包整体流程, 包括UI界面、相机调用和释放、与so动态库的交互、与服务器的交互等
- so动态库打包图像质量和动作活体算法的所有模型加载和逻辑判定代码, 只通过固定的接口与外界交互
为什么调用逻辑要这样设计?
- SDK采用模块化设计, 打包了活体检测的整体流程, 方便嵌入各个APP中, 也方便后续的升级和维护
- so动态库用c++编写, 安卓通过JNI进行交互, IOS可以直接调用, 优点如下
- 安卓与IOS系统通用, 不需要重复开发
- 方便后续升级和维护, 直接换包即可
- 处理速度快
工程上做了哪些优化?
- 内存管理
- Android采用独立线程对采集的每张图片做分析, 同时控制线程数量, 如果数量超出阈值, 丢弃图片
- JNI的对称映射
- Java层对象保留c++层同名对象的指针, java对象可以通过该指针直接操作c++对象
- 该映射替代JNI交互时多余的复制动作, 加快处理速度
- 通过finalize函数在java对象自动回收时销毁对应的c++对象, 方便内存管理
- 大小优化
- 重写抖动检测中用到的opencv底层逻辑, 因此没有opencv.so库依赖, SDK体积减小
- 速度优化
- Java层多线程做图片分析
- C++层开启ncnn库多线程做前向推理
- 体验优化
- 模型迭代, 提升准确率
- 修改了用户提示逻辑, 交互更加合理
备注
ColorTexture
- 活体与非活体,在RGB空间里比较难区分,但在其他颜色空间里的纹理有明显差异
- HSV空间人脸多级LBP特征/YCbCr空间人脸LPQ特征, 画出每个通道的直方图, concate然后交给SVM做分类
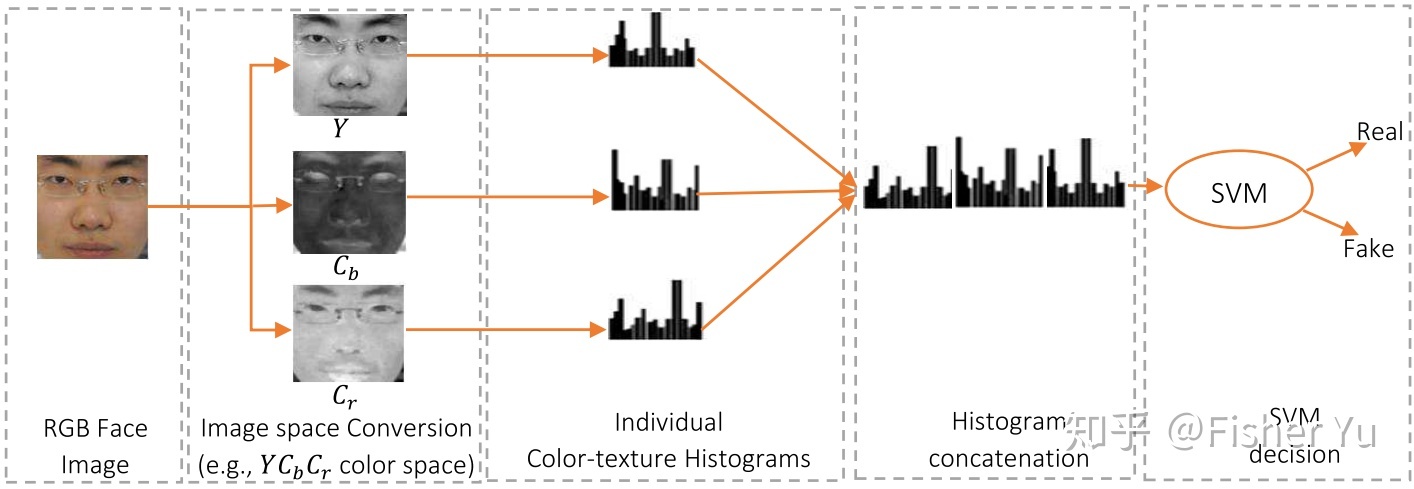
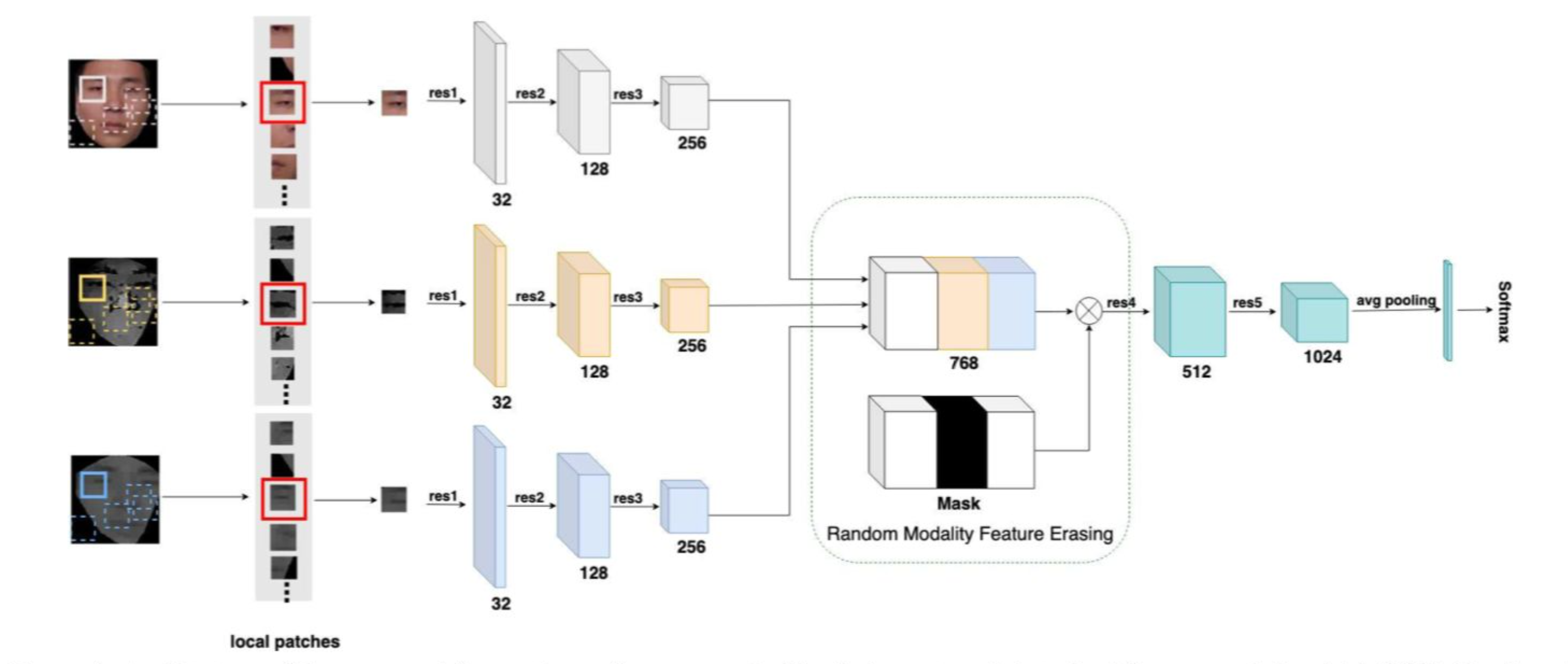
FaceBagNet
- 用随机截取的人脸区域代替完整人脸来训练CNN网络
- 在训练中随机去掉某种模态的特征,以增强泛化
- 提取特征的Backbone设计主要参考ResNext
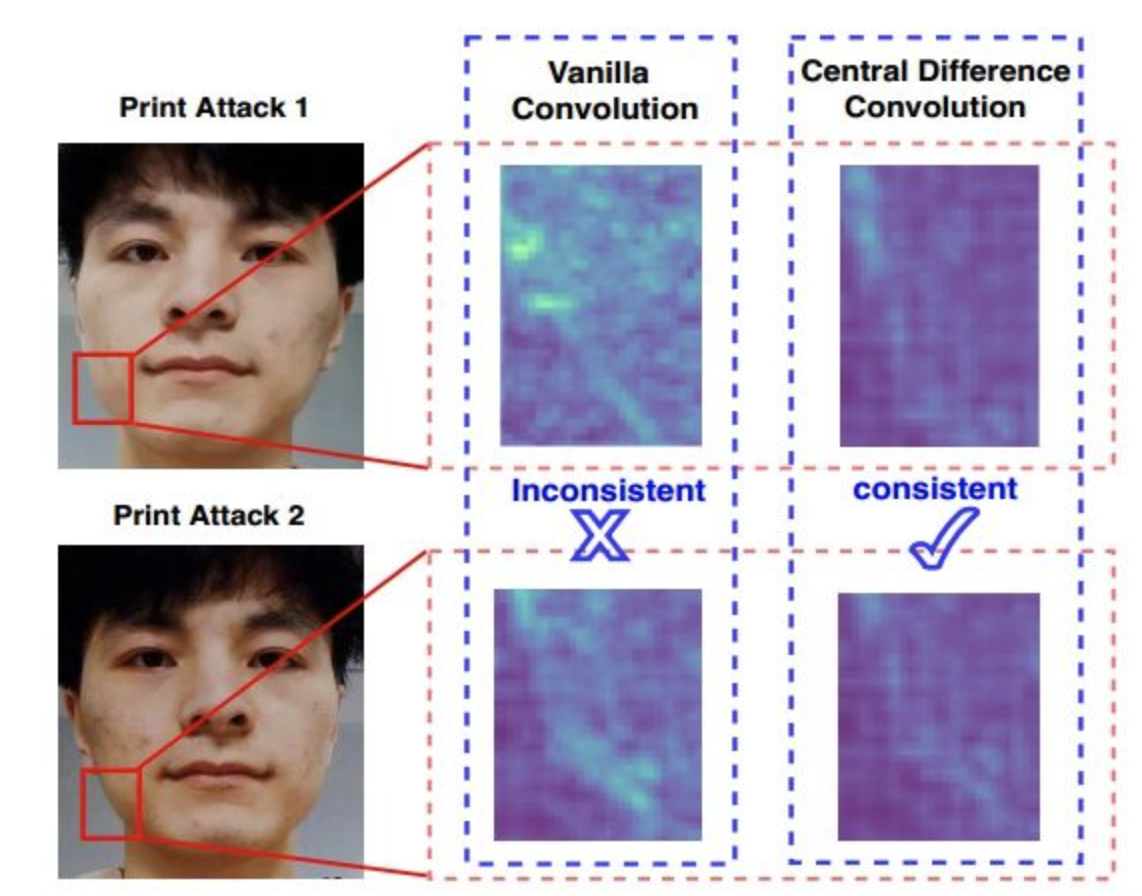
CDCN
- 提出了中心差分卷积CDC,普通卷积非常容易受到光照camera型号等影响,而使用CDC后网络更能捕捉到spoofing的本质特征,且不容易受到外部环境的影响
- 引入NAS来解决FAS问题
SGTD
- 为了更好表征spatial信息,提出基于空间梯度幅值的 Residual Spatial Gradient Block (RSGB)
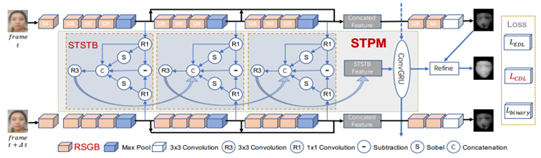
- 为了更好表征temporal信息,提出多级短长时时空传播模块 Spatio-Temporal Propagation Module (STPM)
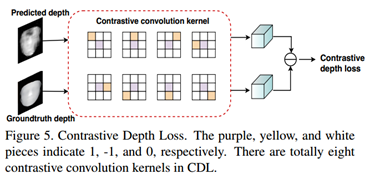
- 为了让网络更好地学习到细节的spoofing patterns,提出了细粒度的监督损失:Contrastive Depth Loss (CDL)
RSGB STPM CDL 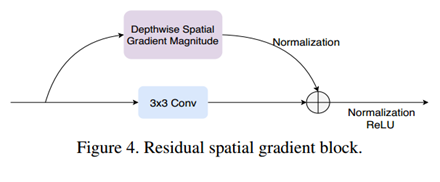
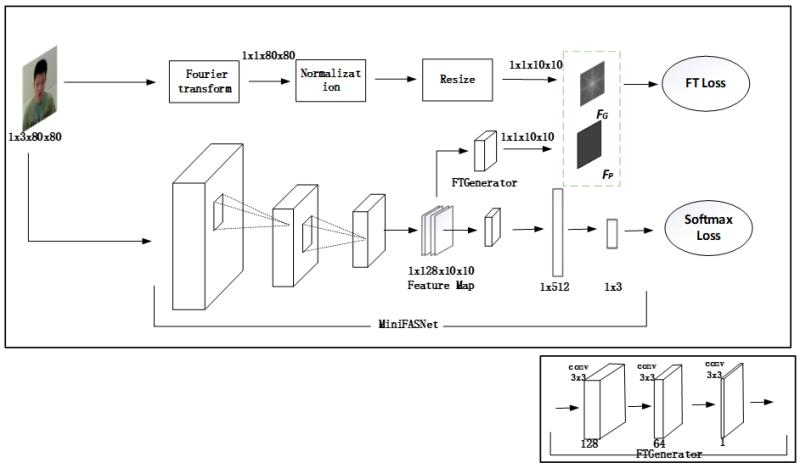
MiniFASNet
- 基于傅里叶频谱图辅助监督的检测方法, 模型架构由分类主分支和傅里叶频谱图辅助监督分支构成
- 视频介绍