背景和目的
什么是行人追踪和行为识别?
- 在多个视角中, 同时追踪多个目标, 并实时识别各自的行为
- 关键词: 实时、多视角、多目标、追踪、行为识别

为什么需要多视角?
- 单视角下目标很容易出现遮挡, 切换视角可以减少遮挡, 有助于行为识别
- 多视角可以在大场景中对目标做持续的追踪, 例如从一个房间到另一个房间

为什么要做行人追踪和行为识别?
- 我们希望帮助商家更好地经营, 包括客流分析、热点区域分布、顾客偏好、异常行为识别等
- 探索智慧商家/无人零售的可行性
- 视频理解
- 监控视频流只是数据的堆砌, 信息是没有结构的, 导致大量的冗余信息存在, 这增加了视频保存、传输、处理、搜索的难度
- 视频理解实际是将这些数据结构化, 这有助于视频压缩, 也方便信息查阅
成果
产品落地了吗, 效果怎么样?
- 公司内部图书馆使用中, 用于同事自助借还书
- 等待与自动商品识别和自助支付流程打通
- 推广受限, 成本太高, 特征提取模型的准确性有待提高
产品有哪些奖项和成果?
- 公司月度最佳项目
- 专利: 《行为识别方法、装置、终端设备以及存储介质》
- 第一作者
- 专利号: CN114764897A
处理思路
处理流程是怎样的?
- 如图所示, 整个流程包括三个模块: 监控端、后台服务器和前端APP
- 监控端获取视频流, 以RTSP流的方式传输给后台
- 后台做实时追踪和识别, 将视频结果以RTSP流的方式传输给APP
- APP展示实时视频结果, 同时也以HTTP的方式与后台交互, 获取智能预警信息和行为分析结果
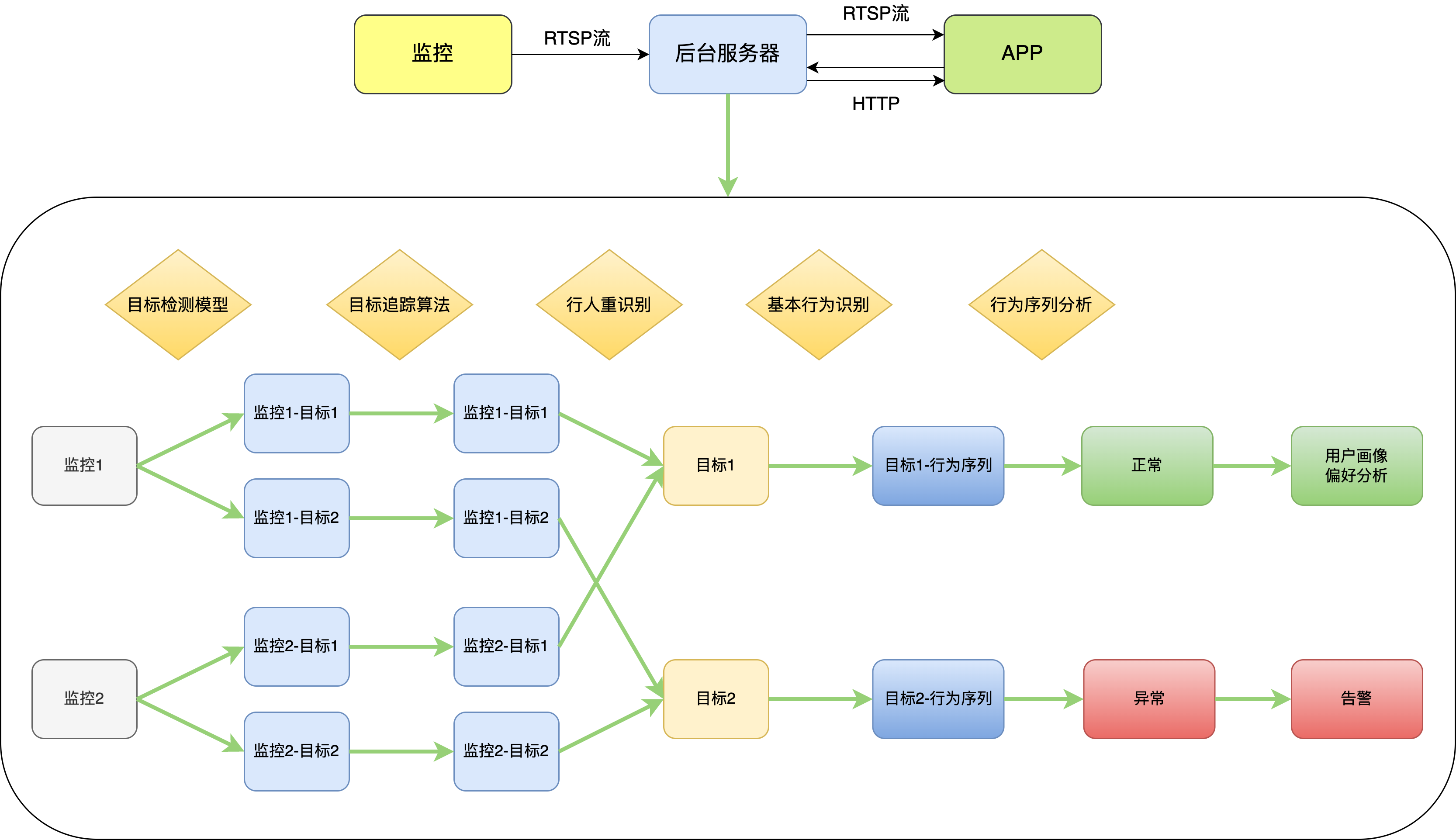
后台怎么做追踪和识别?
- 所有视角做目标检测, 得到检测框
- 所有视角各自做目标追踪, 得到视角内目标(基于同一视角内前后帧之间检测框的运动特征和外观特征相似度)
- 各个视角追踪的目标在视角间做行人重识别, 得到全局目标(基于不同视角的当前帧之间检测框的外观特征相似度)
- 对全局目标做基本行为识别, 得到目标的基本行为序列
- 分析基本行为序列, 判断高级行为
遇到的挑战 - 算法开发
如何做追踪?
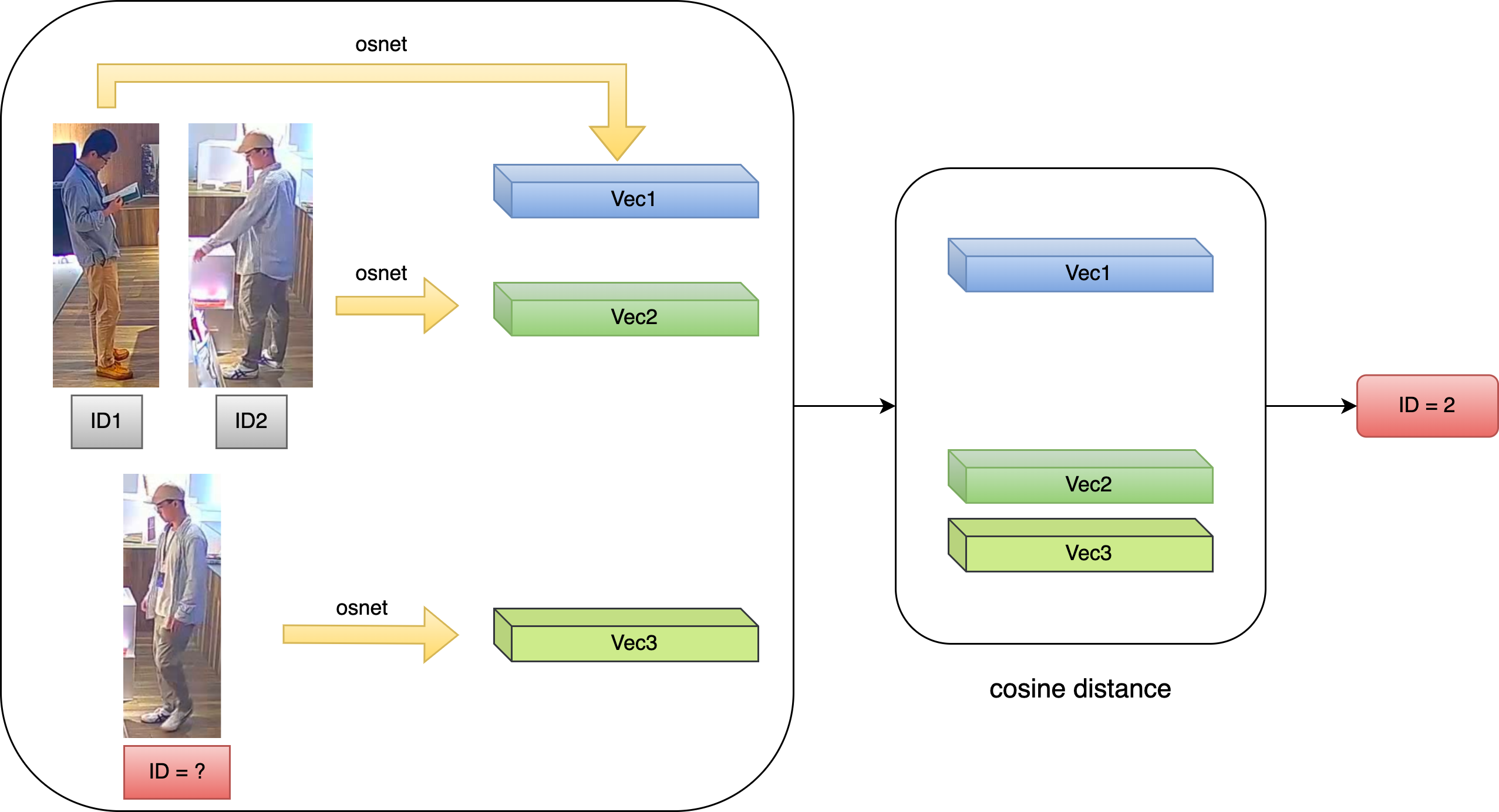
- 基于外观特征相似度
- 目标重识别(REID)算法. 原理是训练特征提取网络, 提取目标的外观特征向量, 然后计算不同特征向量之间的余弦距离. 由于同一目标的特征向量之间的余弦距离会比不同目标的更小, 从而可以进行匹配
- 优点
- 准确度较高
- 缺点
- 外观突变时(如遮挡), 容易导致外观匹配失败, 目标丢失
- 特征提取和余弦相似度匹配的计算量大, 比较耗时
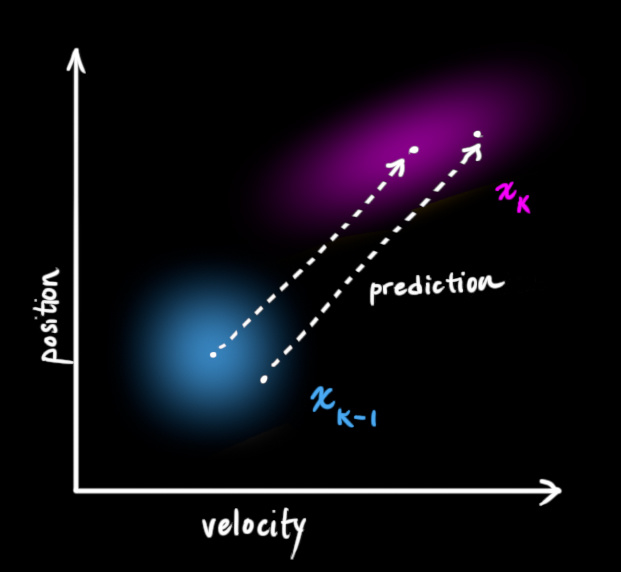
- 基于运动特征相似度
- 卡尔曼滤波算法. 原理是根据上一帧中已知目标的位置、大小、速度, 可以预测当前帧该目标位置的均值和协方差, 然后与当前帧的检测框进行匹配. 匹配上的检测框可以用于预测目标在下一帧的位置
- 优点
- 与外观无关, 即使发生部分遮挡, 也能完成匹配
- 计算量小, 速度快
- 缺点
- 目标交错时可能跟踪出错

如何提升追踪的准确率和效率?
- 二者结合: 基于运动+外观特征相似性度的匹配
- 每一步都提取检测框的外观特征, 并且预测目标在当前的位置均值和方差, 同时做运动特征和外观特征的相似度匹配
- 优点
- 基于运动和外观特征匹配的方法可以优势互补, 目标交错和外观突变时都不再匹配错误
- 缺点
- 由于每一步都需要提取所有检测框的外观特征, 计算量较大, 速度较慢
- 如果目标短暂消失, 然后再次出现, 会被误认为是新目标
- 外观和运动特征匹配出错一次就会影响后续的追踪结果
目标丢失 新目标 

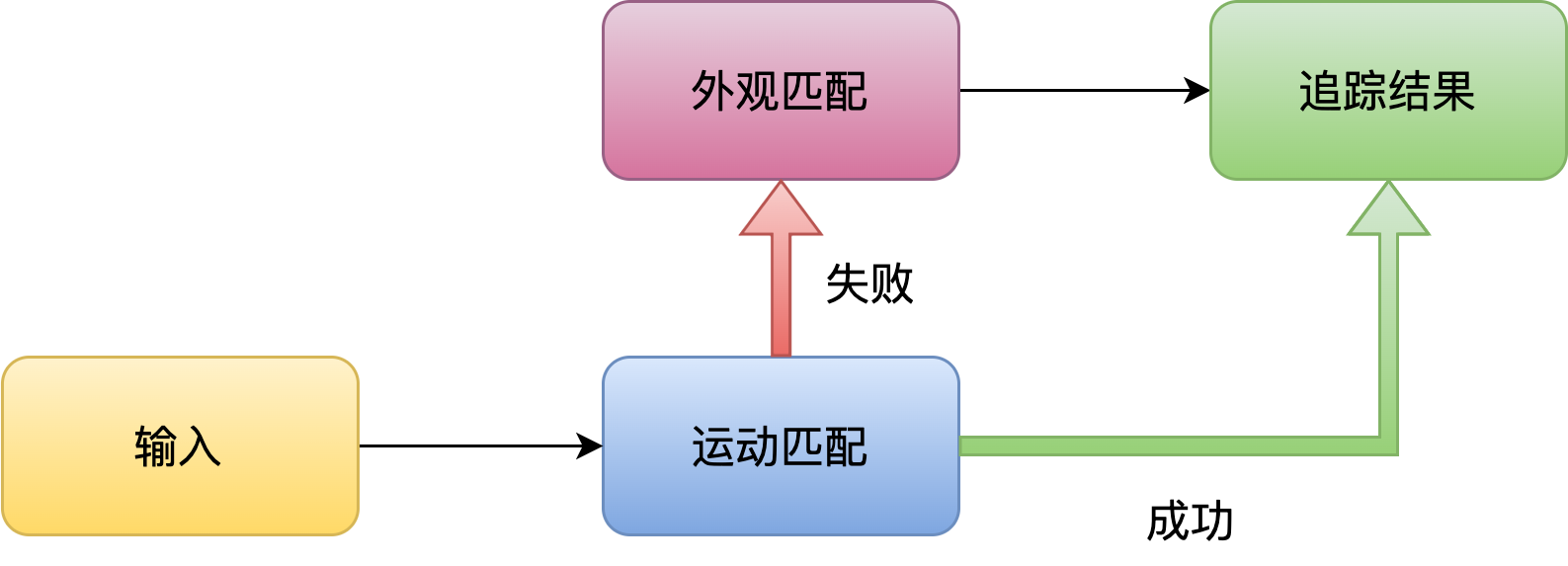
- 更快的匹配方式: 先运动特征匹配, 再外观特征匹配
- 运动特征的相似性足够完成大多数情况下的匹配, 此时外观特征提取不是必要的, 而且会占用计算量, 降低效率
- 人眼的追踪也是类似, 大多数情况下都是基于目标位置进行追踪, 只有必要时才会仔细观察外观进行目标区分
- 所以先做运动特征匹配, 在匹配失败时(如目标附近有多个检测框)再提取外观特征进行识别, 可以节约算力, 提升效率
- 提升稳定性: 逐层匹配机制
- 定期提取已知目标的外观特征保存, 同时保存目标上一次更新的时间. 检测框按目标的更新时间逐层匹配, 更新时间越近的目标越先匹配
- 如果目标短暂消失, 检测框可以通过外观特征与一段时间之前的目标重新匹配, 而不是被误认为新目标, 这使得追踪结果更加稳定
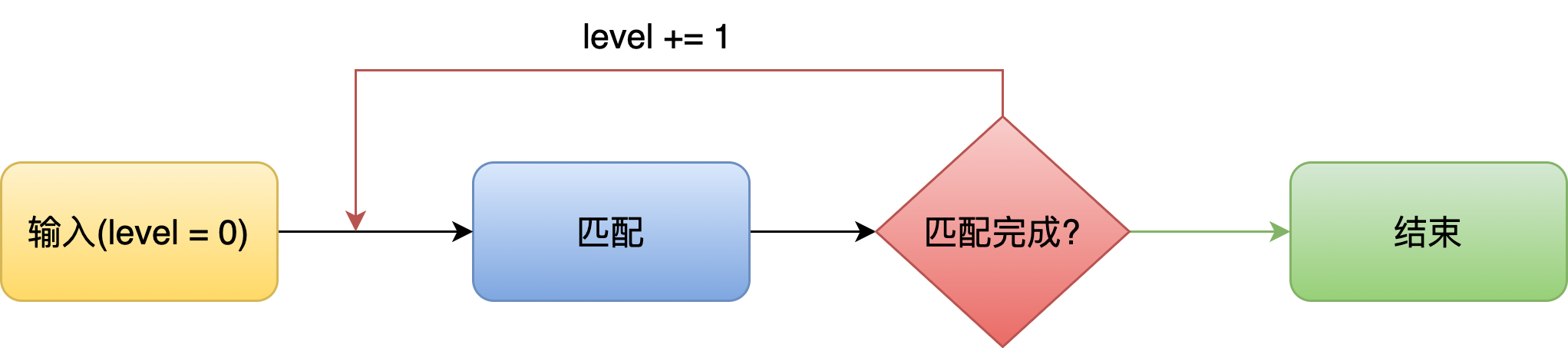
目标丢失 重新匹配 
- 提升准确率: 外观校验
- 独立进程, 校验同一个目标的外观特征长期序列是否保持一致, 防止短期外观匹配失误导致的长期跟踪错误
哪些行为需要识别?
- 定位: 书店
- 正常行为: 取书、阅读、坐、站、走
- 异常行为: 打电话、举手(需要服务)
- 目的
- 取书、阅读行为帮助建立用户画像, 用于用户偏好分析
- 用户停留时间、轨迹用于客流分布和热点区域分析
- 打电话、举手等行为用于识别异常, 辅助管理
如何做行为识别?
- 人体关键点 + 规则
- 规则不好确定, 导致结果不准确
- 算力要求较高
- 通过独立帧做分类
- 优点
- 一些基本动作具有外观差异, 如取书、阅读等, 很容易分辨
- 计算量小, 速度快
- 缺点
- 很容易误判
- 有些动作需要前后帧信息,如伸手和缩手, 单靠一帧无法判断
- 无法统计取书次数
阅读 取书/放回 误判 


- 优点
- 通过连续帧做分类
- 数据预处理
- 下采样、裁剪、缩放、padding等
- 目的: 保持图片不变形, 保留有效信息, 丢弃无关信息
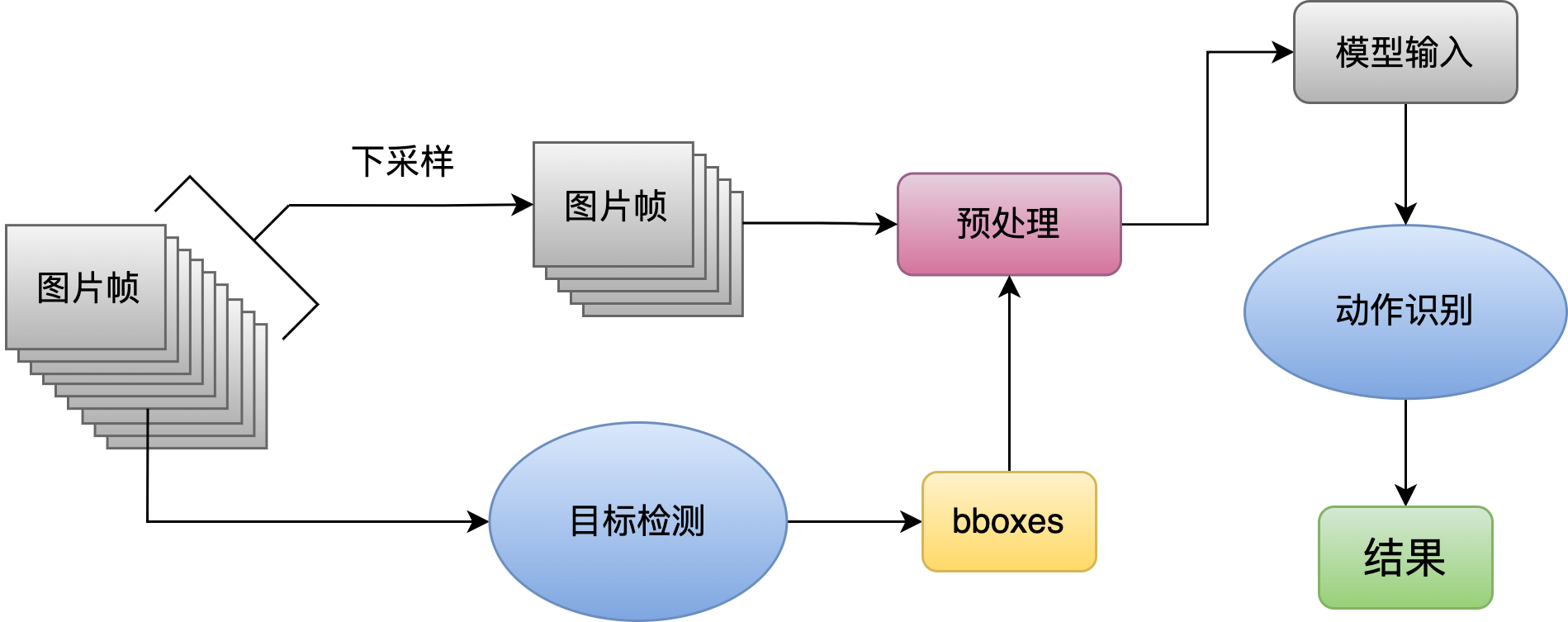
取书 放回 

- 数据预处理
遇到的挑战 - 算法部署
如何做到实时处理?
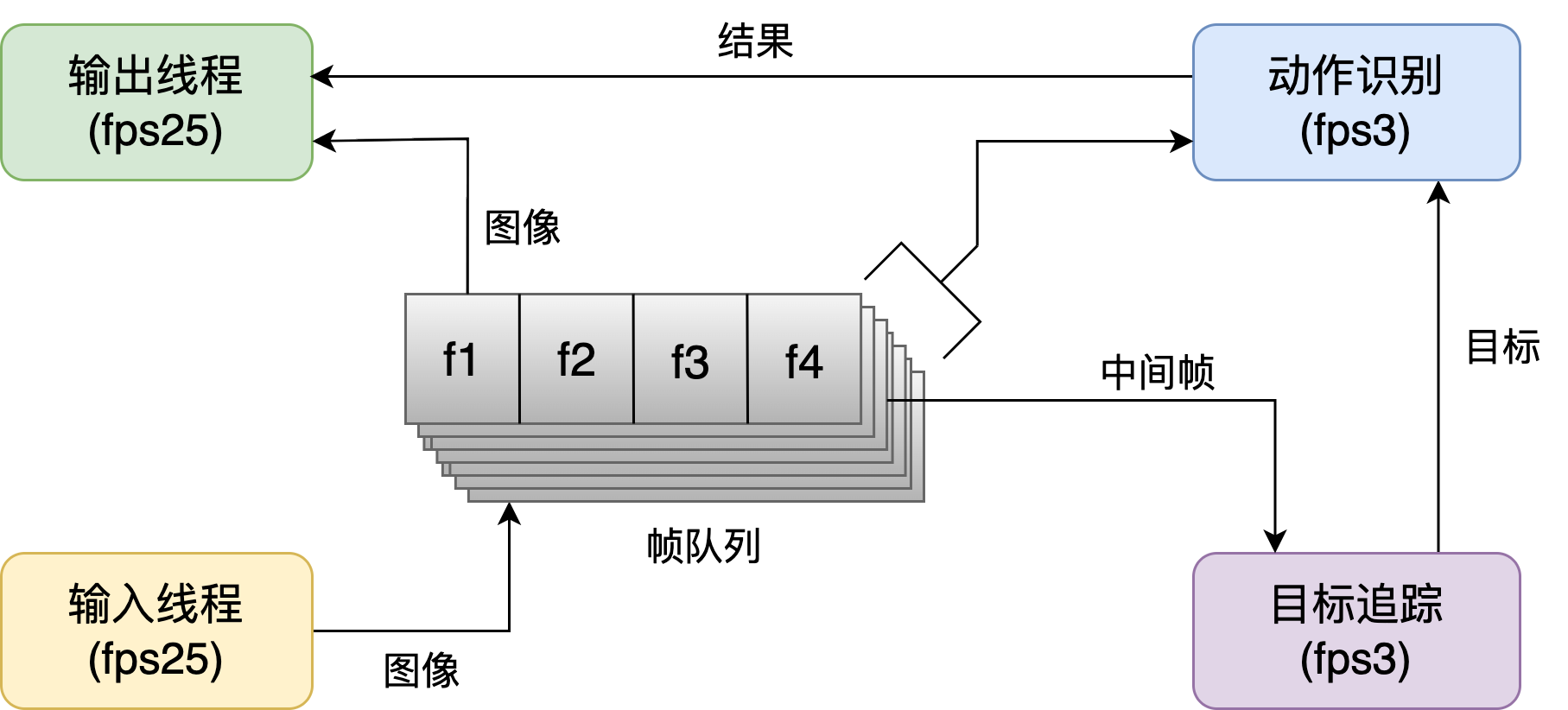
- 必要的处理步骤: 输入视频流、目标追踪、动作识别、输出视频流
- 将整个过程流水线化, 交给4个独立线程按照各自的fps分别处理, 类似CPU的流水线, 线程间共用帧队列
- 流水线大大减少了等待时间
- 保证了输出视频的流畅度, 同时降低了推理过程的fps要求
- 空间换时间, 保证推理速度
- 目标追踪阶段, 所有视角的实时帧stack, 得到一个 (n_imgs * img_shape) 的输入矩阵, 模型只做一次前向推理, 所有图像并行, n_imgs(视角数量) 对处理时间的影响忽略不计
- 动作识别阶段同理, 所有cropped_clips做stack操作, 得到 (n_clips * clip_shape) 的输入矩阵, 只做一次前向推理, 所有clip并行, n_clips(追踪目标数量) 对处理时间的影响忽略不计
输入线程中不同视角的画面不同步怎么办?
- 原因
- 画面不同步的原因是不同视角的时延不一致, 时延的产生是opencv缓冲区导致, 缓冲区可以避免网络波动导致的卡顿
- 但是由于不同视角的TCP连接建立的先后顺序不同, 导致不同缓冲区的有效长度不一致, 从而产生画面不同步问题
- 解决办法
- 自建长度为10帧的队列做为缓冲区, 读取opencv最新帧插入队列
- 所有队列满时, 按照fps25的速度同步读取每个队列
- 这样既保留了缓冲区原本的作用, 又同步了时延, 保证了画面的一致性
| 画面不同步 | 画面同步 |
|---|---|
 |
 |
输出时如何实时传输视频流?
- 通过subprocess模块, 建立python和FFmpeg之间的通道
- Python按固定的fps将推理结果写在图片帧上, 然后传入通道
- FFmpeg接收图片帧, 然后用H264编码
- 相比mpeg4编码方式, H264压缩效率更高, 保证清晰度同时有更小的数据量
- FFmpeg将编码后的数据给到DarwinStreamingServer(实时流媒体播放服务器程序), 以rtsp协议直播视频
